PelikanをArmで飛ばす: Tau T2A VMを使った冒険をさらにディープダイブする
シンプルな最適化とコード変更なしで、MomentoがGoogleのArmベースVMのスループットを3倍にした方法をご覧ください.


Share
私たちが世界最速のキャッシュであると言うとき、それは総合的な意味を持っています。スタートから結果を出すまで、私たちはより速いスケーリング、より速いイテレーション、より速い市場投入を目指しています。このブログでは、高速化を実現するための2つの重要な要素、開発者の生産性と一貫したテール・レイテンシーに焦点を当てます。
Momento Cacheは、TwitterのキャッシュのベストプラクティスをまとめたオープンソースのキャッシュエンジンであるPelikanをベースに構築されたオープンコアです。PelikanはTwitterのスケールで実稼働しており、トップクラスの研究機関との共同研究の恩恵を受けています。Pelikanは最近Rustで全面的に書き直され、マルチワーカーのサポート、データプレーンとコントロールプレーンの両方にプロトコルを追加し、優れたTLSパフォーマンスを達成しました。私たちは、本番環境での使用を推奨するRustバージョンを採用しました。
私たちはTwitter の Pelikanのチームと密接に協力し、エンジンをチューニングし、構成を最適化し、コストとパフォーマンスの最適なVM上で動作するようにしています。これにより、チューニングや設定なしで、高い可用性とスケーラビリティ、パフォーマンスをお客様に提供することができます。
GoogleのArmベースのT2A VM用にPelikanをチューニングすることについての大まかな考察の続きとして、このブログでは、私たちが行った具体的な最適化について深く掘り下げます。ここでのアプローチは、私たちが別の投稿で概説したことを包含していることは注目に値します。
高性能システムを構築するための4つのヒント
全結果と方法論については続きをお読みいただきたいですが、いくつかのハイレベルな要点は以下の通りです:
T2A-standard-16の単一VMの2ms p999サービスレベル目標(SLO)で、チューニングなしで340K RPSに達することができました。
シンプルなシステム・チューニング(コアの固定化)により、スループットが3倍になり、2ms p999 SLOで100万RPSを超えました。このチューニングはx86アーキテクチャでも同様の改善をもたらしました。
Google CloudのTau T2A VM上でのArm用Pelikanのチューニング
私たちは、T2A VM上でのPelikanのチューニングの努力に大変驚きました。動作させるために必要な変更はゼロでした。私たちは、いくつかの簡単な最適化を行っただけで、コードに手を加えることなく、スループットをすぐに3倍にすることができました。
テスト環境のセットアップ
私たちは、Pelikanのクライアント側のレイテンシを2ms@p999というSLOに設定しており、私たちの目的は、SLOに達する前に処理できるスループットを最大化することでした。このスループットは、ホットキーやホットシャードに対する耐性を示すため、非常に重要です。ホットキーやホットシャードは、人気のあるアイテムが平均的なアイテムよりも何桁も多くリクエストされる可能性があるため、キャッシュにとって悪名高い問題です。さらに、SLOに違反することなくVMから処理できるスループットは、顧客に代わってコストを最適化するのに役立ちます。
260バイトのアイテム(4バイトのキー、256バイトの値)を80:20のリード:ライト比率で使用し、4つのrpc-perf VM(T2A-Standard-48)間で合計1,024の接続を行い、同時実行を推進しました。私たちは、SLOに違反することなく維持できるスループットを見つけるために、10K RPSの単位で負荷を増やしました。
rpc-perf and Pelikan configurations
rpc-perf
[general]
protocol = “memcache”
service = true
threads = 256
admin = “0.0.0.0:9090”
[target]
endpoints = […] # list of IP:PORT for each endpoint
[request]
ratelimit = “2500” # rate was increased using admin port
[[keyspace]]
commands = [
{ verb = “get”, weight = 8 }, # 80% read
{ verb = “set”, weight = 2 }, # 20% write
]
length = 4 # 4 byte keys
values = [ { length = 256 } ] # 256 byte values
Pelikan
[admin]
host = “0.0.0.0”
port = “9999” # note: different port numbers were used for each instance
[server]
host = “0.0.0.0”
port = “12321” # note: different port numbers were used for each instance
[worker]
threads = 5
[seg]
hash_power = 24
heap_size = 25769803776
segment_size = 1048576
eviction = “Fifo”
私たちのセットアップでは、1つのVMに2つのPelikanプロセスがあります。各Pelikanプロセスは、I/O、リクエスト解析などを処理する5つのワーカースレッドを持つように設定しました。各プロセスはまた、すべてのキーバリューのアクセスを処理する専用のストレージスレッドを持っています。現代のコンピュータアーキテクチャは、DRAMに保存するタイプのキーバリューに対して、チャネルあたり毎秒何百万ものアクセスを提供することができます。すべてのメモリ・アクセスをシリアライズすることで、ストレージ・コードを単純化し、データ破損の可能性を大幅に減らし、厄介なデータ・レースをほぼ排除します。
T2A VMで事前に調整された数字
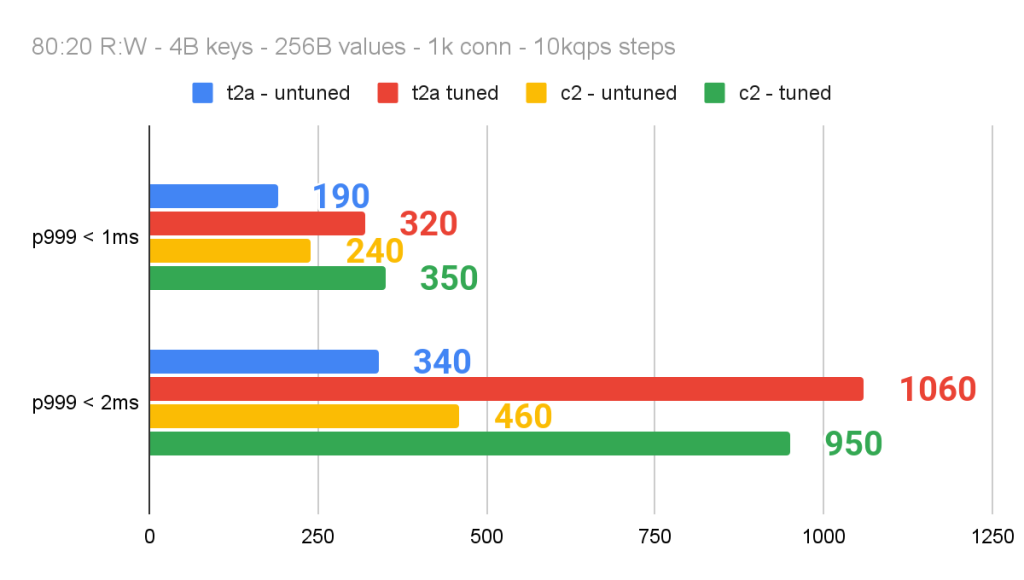
チューニングなしで、t2A-standard-16 VMの2ms p999 SLO内で340K RPSを駆動することができました。同様に、x86ベースのC2 VM(C2-Standard-16)は、SLO内で460K RPSを駆動しました。これは素晴らしかった!我々は、より高速にするために、いくつかの簡単なシステム・チューニング(コードの変更はなし)を行いました。
コンテキストの切り替えについて
コンテキストの切り替えほど著しくパフォーマンスを低下させるものはありません!次の簡単な練習を考えてみましょう: まず、頭の中でAからZまでをできるだけ速く反復する。次に、1-26を数える。次に、A1、B2、C3、D4……と数えてみる。3番目のステップは、1番目と2番目のステップの合計よりも明らかに遅いことに気づくだろう。私たちの脳は、(主にアルファベット内の各文字の位置をキャッシュすることによって)3番を実行し続ければ適応するだろうが、現実の世界にはもっと多くの非決定性があり、私たちのVMプロセッサは、これら2つの全く異なるタスクを処理するために、高価なコンテキスト・スイッチを実行し続けます。
分散キャッシュの性能は通常、カーネル空間で費やされる時間によって支配されます。イベント処理とソケットI/Oです。ソケットI/Oはデータ量が多く、メモリアクセスで構成され、ソケットバッファにデータを取り込むためのパケット処理と並行して行われます。カーネルは両方のデータを移動させなければならないため、競合が発生します。最後に、マルチスレッドプロセスや複数のプロセスによる高負荷の下では、コンテキストスイッチングのオーバーヘッドが大きくなり、コアやCPUのマイグレーションがあるとさらに悪化します。
仮説1:ネットワーク・スレッドを特定のコアに分離することで、コンテキスト・スイッチングを減らし、スループットを向上させることができる。
アプリケーションからは見えないパケット処理は、カーネル空間で実行されるソフトIRQハンドラのセットによって処理されます。カーネル・スレッドにはより高い優先順位があり、カーネルは通常、入力されるシグナルをタイムリーに処理するために、ユーザー空間のスレッドを不随意にコンテキスト・スイッチすることに何の抵抗もありません。
仮説2:アイソレーションによる影響は、負荷が高いほど顕著になる。
低負荷時には、カーネルは自身のスレッドやキャッシュプロセスのユーザー空間のスレッドをそのままにしておくという、かなり良い仕事をすることができます。別の言い方をすれば、多くのコアが利用可能であれば、サービスを受けるためにコアをまたいでスレッドを移動させたり、コンテキストを切り替えたりする必要はありません。一方、高負荷時には競合が多くなり、パケットをタイムリーに処理するために、カーネルはコア間でスレッドをスラッシュすることを余儀なくされるかもしれません。
仮説3:テイルレイテンシーは、コンテキストの切り替え頻度が低いほど敏感であり、p50よりも恩恵を受ける。
高負荷時でさえ、リクエストの中には中断を経験しないものもあります。そのため、p50や平均的なレイテンシーでは、その影響はあまり見えないかもしれません。平均レイテンシやp50レイテンシだけを最適化するのであれば、わずかな利益のために、この作業を優先することはないかもしれません。一方、先に述べたように、これらのレイテンシは重要であり、もっと重視されるべきです。
コアピニングでPelikanを飛ばす
Pelikanの最初のチューニングは、Pelikanスレッドとパケット処理の両方において、不本意なコンテキストスイッチの数を減らすことに主眼を置きました。私たちのシンプルなアプローチは、以下の3つのステップで説明されています。
VM上のコアのトポロジーを理解する。これには、物理 CPU の数、各コアがどの CPU にマッピングされているか、どの物理 CPU がネットワークトラフィックを処理しているかを理解することが含まれます。T2A-Standard-16には、16コアの物理プロセッサが1つあります。これは、C2 および T2D VM ファミリではより重要です。
コアのトポロジーを念頭に置きながら、Pelikanのスレッドを特定のコアに固定する。それぞれ6スレッドからなる2つのPelikanプロセスで、合計12個のアクティブなスレッドがあります。私たちは、不要なコンテキストの切り替えを最小限にするために、これら12個のスレッドをそれぞれ明示的にコアに固定しました。とはいえ、スレッドがコア上で繰り返しコンテキストを放棄する原因となる割り込みの最終的な原因が1つありました:ネットワークI/Oです。
受信/送信(RX/TX)キューを特定のコアに固定する。我々が確立したように、コンテキストスイッチは高価であり、パケットを処理するための信号は、ユーザ空間のスレッドよりも高い優先度を得ます。T2A-Standard-16 NICは、最大16個の受信/送信キュー(各コアにつき1キュー)をサポートしますが、デフォルトでは8キューで起動し、最初の8コアに固定されます。私たちのベンチマークでは、Pelikanのスレッドを95%以上の使用率に保つには、4つのキューのペアで十分であることがわかりました。
全体として、12個のPelikanスレッドが特定のコアに固定され、4個のRX/TXキューがそれぞれのコアに固定され、ネットワークスループットやパケット処理でボトルネックになることはありませんでした。
結果
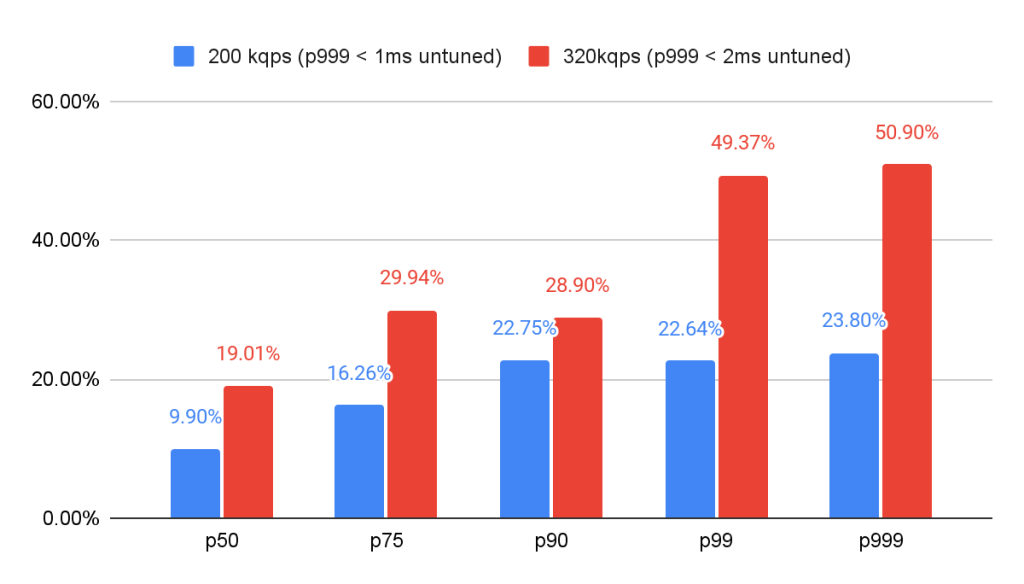
コアのピンニングにより、2msのp999 SLO内で処理できる負荷を3倍*にすることができました。320K RPSでは、p999でレイテンシを50.8%削減できました。コアピニングはまた、T2A-Standard-16がC2-Standard-16を上回ることを可能にしました。
ネットワークを自分のコアに分離し、アクティブなPelikanスレッドを自分のコアに固定することで、パフォーマンスが向上しました。コンテキストスイッチングの正確な影響はまだ定量化中ですが、スループットへの影響から、コアの固定化の有効性については安心しており、最初の仮説を検証することができます。
コアのピン止めの影響は、負荷が高いほど顕著であったが(仮説2)、200K RPSでもp999に意味のある(23%以上)影響が見られました。320K RPSでは、コアのピン化はp999レイテンシを50%以上低下させました。
このような継続的な改善努力のROIは、p50レイテンシでは最小で、200K TPSでのレイテンシ削減はわずか10%でした。平均レイテンシやp50レイテンシに過度に注目していると、これらの投資を過小評価したくなるかもしれません。一方、テールレイテンシの重要性を十分に認識し、それを測定、報告、最適化している者にとっては、高負荷時のp999レイテンシを50%削減できるこの取り組みは非常にROIが高く見えます。
チューニングによる待ち時間の短縮
そして何より、我々のテクニックは、若干劇的ではないものの、x86ベースのC2 VMにも同様の影響を与えました。コアの固定化により、Arm ベースの T2A VM の 2ms p999 SLO で 3 倍のスループット向上が得られましたが、x86 ベースの C2 VM では 2.7 倍でした。
C2 は、コアのピン止めなしで T2A を 35% 上回りました(460K RPS 対 340K RPS)!しかし、両方のコアピンニング後、T2Aは1M RPSのしきい値を突破したが、C2インスタンスは950K RPSでピークに達しました。言い換えれば、コアの固定化だけで、2ms p999 SLO で x86 を上回ることができました。
レッドラインへのチューニングの影響
まとめ
世界最速のキャッシュを提供するために、Google Cloudとパートナーシップを組み、このような最適化を実現できたことは、とてもエキサイティングなことです。私たちのチューニングはまだ始まったばかりで、今後もお客様のためにコストとパフォーマンスを最適化し続けることを期待しています!
Share





