DynamoDB Data Modeling Series
1.DynamoDBのデータモデリングで本当に重要なことは?
2.DynamoDBのセカンダリインデックスはどれを選ぶべきか?
3.最適化されたDynamoDBセカンダリインデックスでコスト削減とスケーラビリティを最大化する (YOU ARE HERE)
4.DynamoDBのシングルテーブル設計:現実
DynamoDB開発者がベストプラクティスを理解し、誤った “単一テーブル設計 “テクニックで後悔するような道を歩まないようにするための、DynamoDBデータモデリングに関するブログシリーズの3回目です。前回は、ローカル・セカンダリ・インデックスとグローバル・セカンダリ・インデックス(LSIとGSI)について紹介しました。今回は、どのテーブルデータがセカンダリインデックスに投影されるのか、そしてそれがスループット消費にどのように寄与するのかを理解するために、さらに深く掘り下げます。また、”シングルテーブル設計 “の最近の傾向の1つであるGSIオーバーロードについて説明し、なぜそれが一般的に悪い考えであり、実際の利点がないのかを説明します。準備はいいですか?さあ、始めましょう…
セカンダリ・インデックスへの射影には、どのベース・テーブルの変更が関係しますか?
セカンダリ・インデックスを定義する際、ベース・テーブルの関連する項目の変更からコピー(投影)される属性を選択することができます:
・ALL ベース・テーブル項目の全ての属性がセカンダリ・インデックスにコピーされます。
・INCLUDE 指定された属性のリストのみがコピーされます(さらに、ベーステーブルとセカンダリインデックスの主キー属性がコピーされます。)
・KEYS_ONLY ベース・テーブルとセカンダリ・インデックスの主キー属性のみがコピーされます。
DynamoDBのセカンダリインデックスに対するメータリングの仕組みは、ベーステーブルへのすべての書き込みが、各セカンダリインデックスへの投影のために考慮されます。ベーステーブルの項目への変更がセカンダリインデックスに関連する場合、それは投影され、投影された項目ビューのサイズに応じて測定される書き込み単位の消費が発生します。セカンダリインデックスに投影されたデータにも、ストレージコストが発生します。このシリーズの最初の記事で説明したように、QueryとScan(セカンダリインデックスで使用できる唯一の読み取り操作)は、すべてのアイテムのサイズを集約し、読み取り単位を評価するために切り上げます。項目の投影ビューを小さく保てば、インデックスのコストは少なくなり、ホットキーの懸念に直面する前にさらに拡張することができます。
セカンダリー・インデックスの投影は慎重に検討する必要があります。ALLは単純に見えますが、非常にコストがかかり、設計全体のスケーラビリティを阻害する可能性があります。本当に必要な属性だけを投影してください。
セカンダリー・インデックスのこの効率方程式にはさらに続きがあります。なぜ私が関連性という言葉を強調し続けるのか不思議に思っていることでしょう。それは、本当に重要だからです!まず、DynamoDBはスキーマの柔軟性を提供しているため、セカンダリインデックスのキーとして定義された属性は、テーブル内のすべてのアイテムに存在する必要はありません(そのテーブルのプライマリキーの一部である場合を除く)。インデックスキーの属性がテーブルの項目に存在しない場合、インデックスへの投影に関連性があるとはみなされません。これを使用して、”スパース “インデックスを作成することができます。これは、必要なデータを最小のストレージコストとスループットコストで見つける、フィルタリングのための強力なメカニズムです。
例えば、何百万というジョブのステータスの詳細を保存しているデータベースがあるとします。ワーカープロセスが “投入済み “ステータスのジョブを簡単に見つけられるようにするにはどうすればよいでしょうか?該当するステータスのジョブに対して、それを示す属性を設定し、この属性をキーとするセカンダリインデックスを作成します。ジョブが完了したら、この属性を削除してください。そうすれば、ワーカーが検討するためのセカンダリインデックスからジョブが見えなくなります。
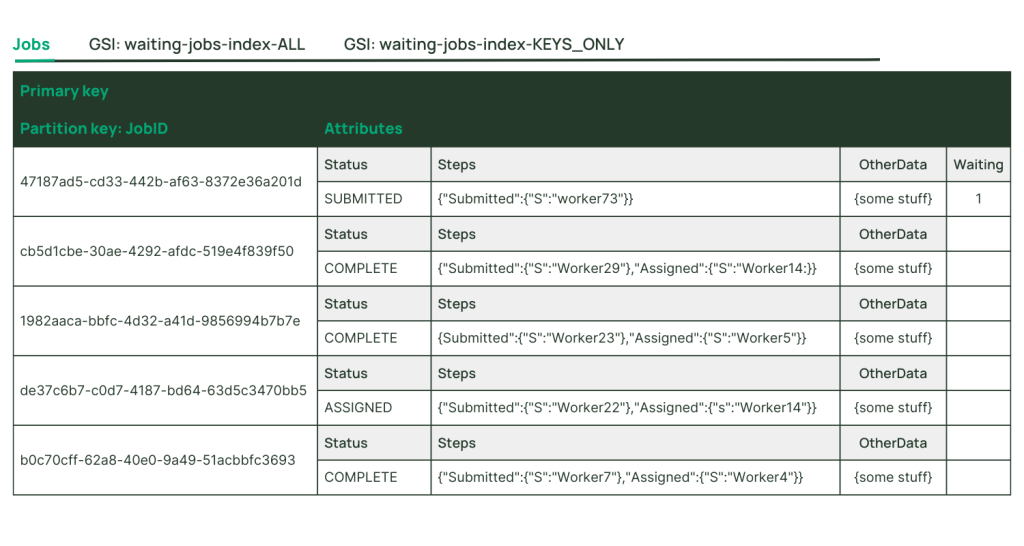
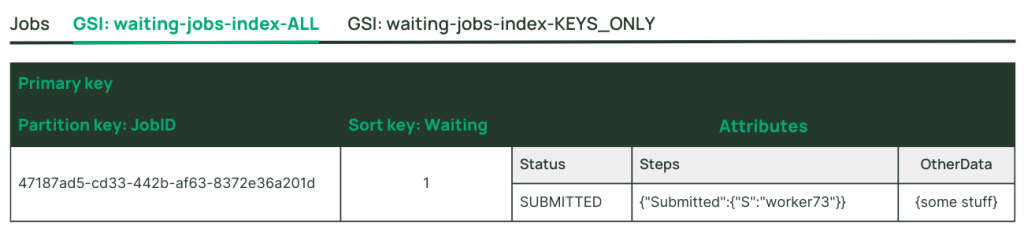
ここで、提出済みステータスのジョブのワークフローの一環として、テーブル内のジョブ項目が5回更新され、キー以外の属性にさまざまな詳細が追加されるとします。これらの属性が提出済みジョブのスパースセカンダリインデックスに投影される場合、インデックスも5回更新される必要があり、大量の書き込みユニットが消費されます。しかし、このスパースなセカンダリインデックスには、これらの属性は必要ありません。そこで、インデックスにはKEYS_ONLYプロジェクションを選択します。読み取り単位の消費を低く抑え、ワーカープロセスのスケーラビリティを最大化し、ストレージを節約し、インデックスプロジェクションのための不要な書き込みを回避します。
これは繰り返す価値があります:本当に必要な属性だけを射影することです。

GSIオーバーロードとは何か?なぜそれが悪いのか?
2017年当時、Amazonのチームは最も重要なワークロードをリレーショナルデータベースからDynamoDBに移行するために懸命に取り組んでいました。彼らは、馴染みのある第3正規形を超え、DynamoDBのアイテムとアイテムコレクションに非正規化することで、データモデリングについて異なる考え方を学んでいました。当時、DynamoDBは1テーブルあたり最大5GSIをサポートしていました。まれに、すべてのアクセスパターンをカバーするために5つ以上のGSIを必要とするテーブルを持つチームがありました。そのようなチームをサポートするために働いている私たちにとって、インデックスの必要性のいくつかは疎であり、重複していない可能性があることに気づかされました。もしかしたら、いくつかの奇妙な適応を使えば、同じGSIを使って複数のアクセスパターンの要求をカバーできるかもしれません。そう、それは最後の手段であり、効率や操作性に大きな影響を与えるが、うまくいくこともありました。私たちはこれを「GSIオーバーローディング」と呼んでいました。
2018年12月になり、DynamoDBはテーブルあたりのGSIの上限を20に増やしました。喜びましょう!これからは醜いオーバーロード・ハックは必要ない……そうでしょう?エンジニアリング・チームはそう考えていたが、「単一テーブルの設計」に不穏な動きが出てきたのです。
不自然で、不必要で、複雑で、非効率的なことをして、全く関係のないデータをただ1つのDynamoDBテーブルに意味もなく押し込むと、そのテーブルのセカンダリインデックスをさらに作成しなければならなくなることがわかりました。
効率や柔軟性、スケーラビリティを優先させるのではなく、厳密に1つのテーブルを目標に設計している場合、テーブルごとのGSIの制限に遭遇する可能性が高くなります。そして、同じように「厳密に1つのテーブル」という強迫観念が、正確に1つのGSIを持ちたいという誤った願望を駆り立て、過負荷につながるのです。これは、さまざまな問題を引き起こします。このテクニックには何のメリットもありません。その理由は…
・プロジェクションのトレードオフは、コストとデザインのスケーラビリティを損ないます。最も一般的なのは、ALLを投影することと、(数値の方が効率的なのに)主キー属性をデフォルトの文字列にすることです。これは痛い!
・セカンダリー・インデックスをスキャンして、気になるデータだけを取り出すという柔軟性が失われます。せっかくの強力な機能が、何の理由もなく失われてしまうのです。
・GSIの素晴らしい点のひとつは、削除して必要に応じて再作成できることです。GSIの削除には何のコストもかかりません。複数のインデックス要件を1つのGSIに混在させ、ある時点でパターンの1つにインデックスを付ける必要がないことに気づいた場合、そのGSIを削除することはできません。そのようなことは避けたいものです。
重要なポイント
要するに、”GSIオーバーロード “には何のメリットもありません。やめましょう!また、コストの最適化やスケーラビリティを重視するのであれば、DynamoDBのセカンダリインデックスを設計する際には、スパース性と最小限の投影を考慮してください。
このシリーズの次の記事では、これまで学んできたことを土台にして、「シングル・テーブル・デザイン」のどこで間違ったのか、そしてなぜそれを正確に1つのテーブルと解釈することが(アマゾンのチームが犯していない)とんでもない間違いなのかを説明するつもりです。
このトピックについて私と議論したい場合、あなたが持っているDynamoDBデータモデリングに関する質問について私の考えを聞きたい場合、または今後の記事で書くべきトピックを提案したい場合は、Twitter(@pj_naylor)で私に連絡するか、メールを送ってください!

Share






