Lambda実行コンテキストにおけるgRPCキープアライブの話
Momentoがどのようにしてタイムアウトをなくし、より信頼性の高いキャッシングサービスを実現したかをご覧ください。

Share
AWS Lambdaを使うと、開発者はインフラを管理する必要なく、トリガーに応じてコードを実行できる。これは開発者のフォーカスをサーバー管理からコード実行にシフトさせ、スケーラビリティとコスト効率を提供します。しかし、このモデルは、特に長時間の接続やkeepaliveメカニズムを扱う際に、ユニークな動作や課題ももたらします。このブログでは、AWS Lambdaの実行コンテキストの再利用の挙動と、サーバーレス環境におけるキープアライブの挙動への影響について、実際の観察と実践的な実験から探ります。
実行コンテキストとは何か?
AWS Lambdaのドキュメントによると、「Lambdaは関数を実行環境で呼び出します。実行環境は、関数の実行に必要なリソースを管理します。” これらの実行環境は、非公式にLambdaコンテナまたはLambdaインスタンスとも呼ばれる。パフォーマンスを向上させ、コールドスタート(コンテナの起動にかかる時間)に関連するレイテンシを削減するために、AWS Lambdaはランタイムと、実行コンテキストと呼ばれる呼び出しにまたがるグローバル変数や静的初期化を再利用することができます。
実験: 呼び出しにまたがるグローバルな状態の持続性
次のNode.jsラムダ関数のスニペットを考えてみよう:
// These are placed outside the Lambda handler to persist across invocations on the same container
const startTime = Date.now();
let numSecondsElapsed = 0;
// This setInterval will start counting from the time this execution context is initialized, and increment numSecondsElapsed every second
setInterval(() => {
numSecondsElapsed += 1;
}, 1000);
// Lambda handler
export const handler = async function(event: any = {}, context: any) {
// Calculate elapsed time in seconds since the start of this execution context
const calculatedNumberMillisecondsElapsed = Date.now() - startTime;
const calculatedNumberSecondsElapsed = Math.floor(calculatedNumberMillisecondsElapsed / 1000);
// Log both elapsed times for comparison
console.log(`Calculated: ${calculatedNumberSecondsElapsed} seconds, Background Task: ${numSecondsElapsed} seconds`);
return {
statusCode: 200,
body: JSON.stringify({
message: `Hello from Lambda! Calculated: ${calculatedNumberSecondsElapsed} seconds, Background Task: ${numSecondsElapsed} seconds`,
}),
};
};このセットアップでは、setIntervalを使用して、Lambda実行コンテキストが最初に初期化されたときから、1秒ごとにnumSecondsElapsedをインクリメントします。このセットアップの目的は、startTimeから直接計算された経過時間と、バックグラウンドタスクによって追跡された経過時間を比較することです。
この関数を60秒以内に10回呼び出した場合の出力がわかるでしょうか?興味深いことに、直接計算されるcalculatedNumberSecondsElapsedは、Lambda実行コンテキストのstartTimeからの時間を計測するため、60秒に近づくインクリメントを表示します。しかし、バックグラウンドタスクのnumSecondsElapsedは、関数がアクティブに実行されている秒ごとにインクリメントするので、おそらく10以下の値を示すでしょう。この矛盾は、バックグラウンド・タスクは、Lambda関数の実際の実行中にのみ計算リソースとインクリメントの機会を与えられるためであり、呼び出し間のアイドル時間にわたって継続的に与えられるわけではありません。
この実験は、サーバーレス関数実行の重要な側面を示しています。Lambdaは実行コンテキストを再利用することで、グローバル変数を保持することができるが、呼び出しの間にこれらのコンテキストに計算リソースを継続的に割り当てることはありません。その結果、setIntervalはLambda関数がアクティブに実行されていない限り実行されません。この動作は、継続的なバックグラウンド処理に依存するアプリケーションを移植する際に、慎重な検討が必要であることを強調しています。
サーバーレス機能におけるkeepaliveの意味合い
Momentoでは、クライアントとサーバーのやりとりは、高性能なオープンソースのユニバーサルRPCフレームワークであるgRPCを使用しています。堅牢な通信を保証するため、gRPC チャネル設定でkeepaliveチェックを実装し、5 秒ごとに ping を送信し、1 秒以内に応答があるように設定しています。当初、これらの設定は、事前に構築されたコンフィギュレーションにおいて、さまざまな環境で標準化されていました。
しかし、AWS Lambdaに代表されるサーバーレス環境では、持続的な接続を管理するための明確な課題が発生します。この複雑さは、私たちのNode.js SDKがLambda環境で不可解な’deadline exceeded’エラー(gRPCで特定のタイプのタイムアウトを表す用語)を経験し始めたときに明らかになりました。これらのタイムアウトの根本原因を理解するために、私たちは dns_resolver、resolving_load_balancer、keepalive などの Lambda 関数で詳細な gRPC トレースを有効にしました。これらのトレースにより、AWS Lambdaのサーバーレス環境内でのgRPC接続のネットワーク通信とライフサイクル管理を見ることができました。
AWS Lambdaでは、各呼び出しは一意のリクエストIDを生成し、特定の実行のためのフィンガープリントとして機能します。gRPCのトレースと一緒にこれらのIDを調べることで、各呼び出しのライフサイクルと関連するネットワークアクティビティを追跡することができました。これにより、ネットワークイベントをLambda関数の特定の呼び出しと直接関連付けることができました。
キープアライブトレースログを見直したときに、注目すべき発見があった。keepalive pingを開始するためにフラグが立てられたリクエストIDが、タイムアウトイベントでログに記録されたものと一致しないことが観察された。例えば
requestID-1 | keepalive | (18) 54.xxx.xxx.xx:443 Sending ping with timeout 1000ms同じコンテナで発生したにもかかわらず、異なるリクエストIDでタイムアウトエラーが発生します:
requestID-2 | keepalive | (4) 54.xxx.xxx.xx:443 Ping timeout passed without responsepingの試行と観測されたタイムアウトエラーとの間のリクエストIDの不一致は、あるLambdaの呼び出し中に開始されたkeepalive pingが次の呼び出しまで処理されなかったことを明確に示しています。これは極めて重要な洞察であり、呼び出しの間にフリーズとスローを繰り返すLambda実行環境の動作が、gRPC keepalive メカニズムに影響を及ぼしていることを確認しました。
Lambda 呼び出しの間の休止状態の間、発信された keepalive ping はコンテナが再度エンゲージされるまで認識されずに宙に浮いたままでした。コンテナが再びアクティブになる頃には、gRPCのkeepaliveのタイムアウトが既に経過していることが多く、keepaliveの失敗が指摘されました。これらのタイムアウトは、gRPC の再接続を必要とし、その結果、サービスにアクセスしようとすると、その後のリクエストタイムアウトにつながる可能性がありました。
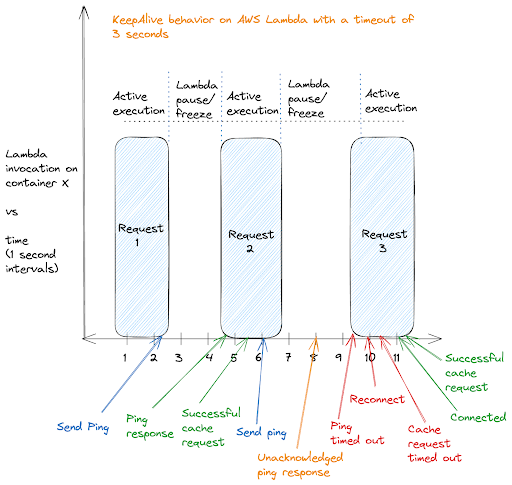
この図は、AWS Lambdaの実行モデルにおけるkeepaliveの動作を視覚的に説明したものです。表示されているのは、同じコンテナ上で 3 つの連続した Lambda の呼び出しで、アクティブな処理と強制的な休止期間があります。最初の2つのリクエストでは、keepalive pingが送信され、すぐに確認されるというスムーズなサイクルを示しており、これは成功したキャッシュリクエストに対応しています。
しかし、この図では、このサイクルの不具合にも注目しています。3番目のリクエストの実行が遅れ、keepalivepingがタイムアウト状態に陥っています。サーバーはこの遅延の間にping応答を送信しましたが、ラムダは非アクティブだったため、それを確認することはありませんでした。この遅延は接続の継続性を中断させ、再接続とリクエストタイムアウトの必要性から明らかなように、Lambdaの呼び出しモデルに固有の遅延がサービスの中断につながるシナリオを強調しています。
AWS LambdaのKeepaliveをオフにする
呼び出し間のアイドル時間が一般的で予測不可能なサーバーレスアーキテクチャの性質を考えると、従来のkeepalive メカニズムは適さないことが判明しました。タイムアウト値を調整する(増やすにせよ減らすにせよ)ことは、heepalive プロトコルとサーバーレス関数の散発的な実行パターンとのミスマッチを修正することにはなりません。その結果、私たちはMomentoのデフォルトのAWS Lambda設定でkeepalive pingを無効にすることを選択しました。
この変更により、クライアント側のタイムアウトエラーが効果的に減少し、キャッシング・サービスのオペレーションがサーバーレス・パラダイムにはるかに適合するようになりました。しかし、このソリューションにはトレードオフがあることに注意する必要があります。例えば、Lambdaの実行コンテキストで接続が長時間アイドル状態のままになっているシナリオでは、keepalive が無効になっているため、システムは接続が切断されたことを迅速に検出できなくなります。これは私たちが受け入れた妥協点であり、長時間の非アクティブを即座に検出することよりも、頻繁なタイムアウトを排除することを優先しています。
主な要点とベストプラクティス
この経験は、サーバーレス環境でサービスをデプロイするためのいくつかの重要な考慮事項を浮き彫りにしています:
・サーバーレス特有の構成: サービスはサーバーレス・プラットフォームの運用ダイナミクスに合わせて調整する必要があります。ネットワーク接続や長寿命接続に関する従来の仮定は当てはまらないかもしれません。したがって、サービス・プロバイダーは、Momentoで行っているように、SDKで環境ごとに異なる事前設定を提供することが重要です。
・プラットフォームの挙動への適応: 実行コンテキストの凍結や解凍など、サーバーレスプラットフォームの挙動を理解し適応することは、サービスの信頼性とパフォーマンスを維持するために不可欠です。
・モニタリングと診断: 詳細なロギングとトレースの実装は、サーバーレス環境に特有の問題を診断し解決するために極めて重要です。ネットワーク関連の問題を診断するには、gRPCが提供するようなネットワークレベルのトレースや、TCPダンプを取得してWiresharkで分析することが必要になることが一般的です。
結論
サーバーレスには、スケーラビリティ、コスト、運用効率の面で大きなメリットがあります。しかし、ネットワーク接続を管理し、アプリケーションの状態を維持する方法を再評価する必要もあります。AWSのLambdaでkeepalive pingの課題を乗り切ったMomentoの経験は、サービスのシームレスな運用を保証するための適応性の重要性とサーバーレスに特化したソリューションの必要性を強調しています。
Share






