DynamoDB Data Modeling Series
1.DynamoDBのデータモデリングで本当に重要なことは何か?(この記事です)
2..DynamoDBのセカンダリインデックスはどれを選ぶべきか?
3.最適化されたDynamoDBセカンダリインデックスでコスト削減とスケーラビリティを最大化する
4.DynamoDBのシングルテーブル設計の現実
数ヶ月前にDynamoDBチームを離れるにあたり、DynamoDBの設計や運用について学んだことを共有する必要があると考えました。AWSで6年間、社内外のDynamoDBのお客様と仕事をする中で、私は幸運にも様々なDynamoDBのデータモデルに触れることができました。DynamoDBが様々な負荷の下でどのようにスケールするか(あるいはスケールしないか)、新しいアプリケーションの要件に柔軟に対応できるか、時間が経つにつれてコスト的に不利にならないか、といった運用の進化も見てきました。
これは、DynamoDBデータモデリングのベストプラクティスに関するいくつかの誤解を正すことを目的として公開する短期連載のパート1です。ここ数年、(AWSマーケティングの助けを借りて)ソーシャルメディアのうわさを通じて奇妙な推奨が進化してきました。私は現実の世界について書こうと思う。DynamoDBチームが、このサービスがミッションクリティカルである他のAmazonチームに対して行っているのと同じアドバイス-最適化の推奨、”single table “についての警告、メトリクスの解釈に関する同じヒント、メータリングのニュアンスに関する同じ詳細、そしてオペレーショナルエクセレンスへのフォーカス-を提供するつもりです。
始める準備はできましたか?この第1回では、DynamoDBで成功するための秘訣を共有することで、このシリーズの土台を作ろうと思います。確かに、この内容を本当に理解するのには時間がかかりました。私についてきてください!近道を知っています。
テーブルの数がすべてではないとしたら、何が本当に重要なのだろうか?
DynamoDBのデータモデリングを最も単純なkey-valueのユースケースを超えて学習する際に、最初に理解する必要がある2つの概念は、1)スキーマの柔軟性と2)アイテムのコレクションです。
スキーマの柔軟性とは、DynamoDBテーブルのアイテムがすべて同じ構造を必要としないことを意味します!実際、スキーマが強制される唯一の属性はプライマリキー属性です。各項目は、正しいデータ型でテーブル用に定義されたキー属性を含まなければなりません。
アイテム・コレクションは、同じパーティション・キー属性値を持つすべてのアイテムの集合です。リレーショナル・データベースに慣れている人なら、アイテム・コレクションをマテリアライズドJOINのように考えることができます。DynamoDBのデータモデルを最適化するためには、ベーステーブルやセカンダリインデックスでアイテムコレクションを使う機会を探したいと感じます。同じアイテムコレクションにあるためには、アイテムも同じテーブルにある必要があります – アイテムコレクションはテーブルのサブセットです。
例えば、ショッピングカートをアイテムコレクションとして表現し、一意のカート識別子(Pete’s Cart)をパーティションキー値とし、カートに追加された各商品の識別子をソートキー値とします。どうやらPeteは野菜よりもコーヒーが好きだが、チョコレートほどではないようです。カート内の各商品タイプの数は、別の(キーではない)属性です。下の画像はそのような商品コレクションを表しています。
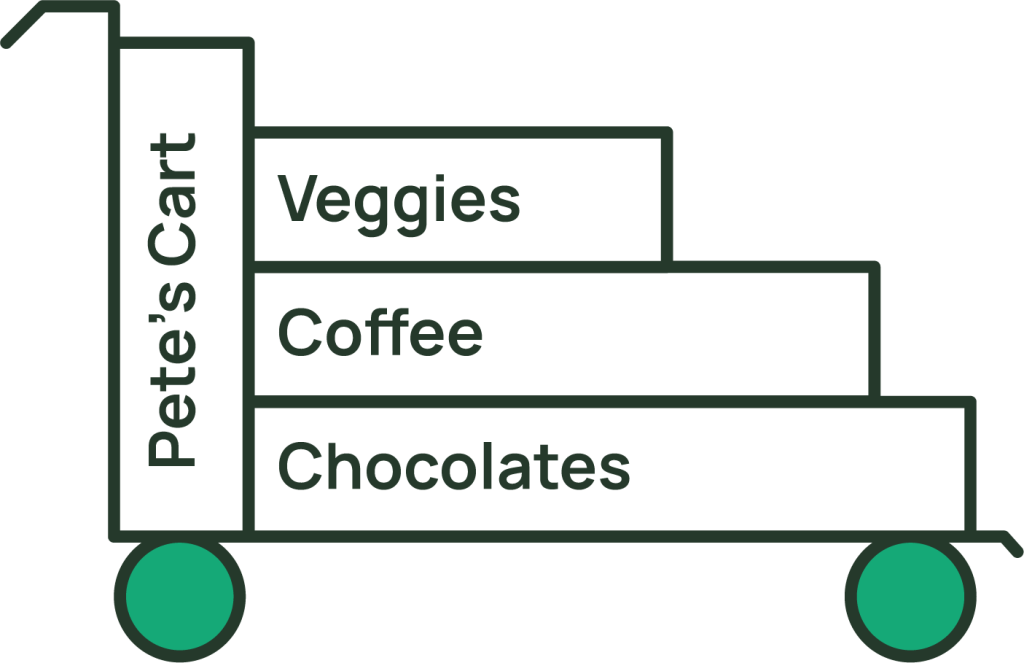
あなたのコードは、下のNoSQL Workbenchのスクリーンショットのように、より厳密な定義を持っています。
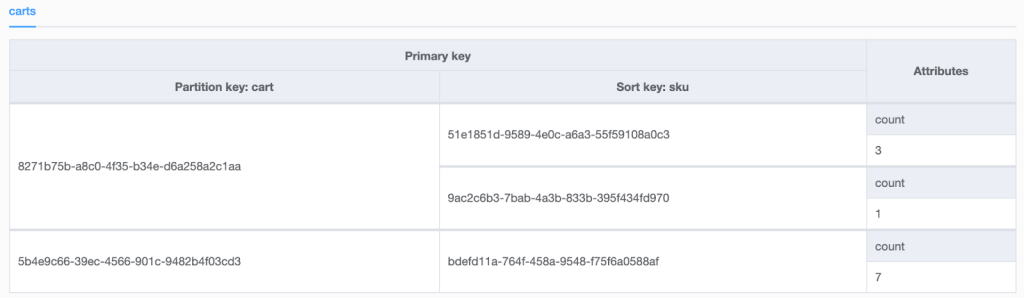
アイテム・コレクションはプライマリ・インデックス(ベース・テーブル)および/またはセカンダリ・インデックスに存在することができます。セカンダリインデックスの詳細については今後のブログで詳しく説明しますので、今回はベーステーブルに焦点を当てましょう。 ベーステーブルのアイテムコレクションには複合プライマリキー(パーティションキーとソートキー)が必要です。ローカルセカンダリインデックス(LSI)がない場合、アイテムコレクションは複数のDynamoDBパーティションにまたがることができます。最初はそうではありませんが、DynamoDBはデータ量の増加に対応するために、アイテムコレクションをパーティション間で自動的に分割します。
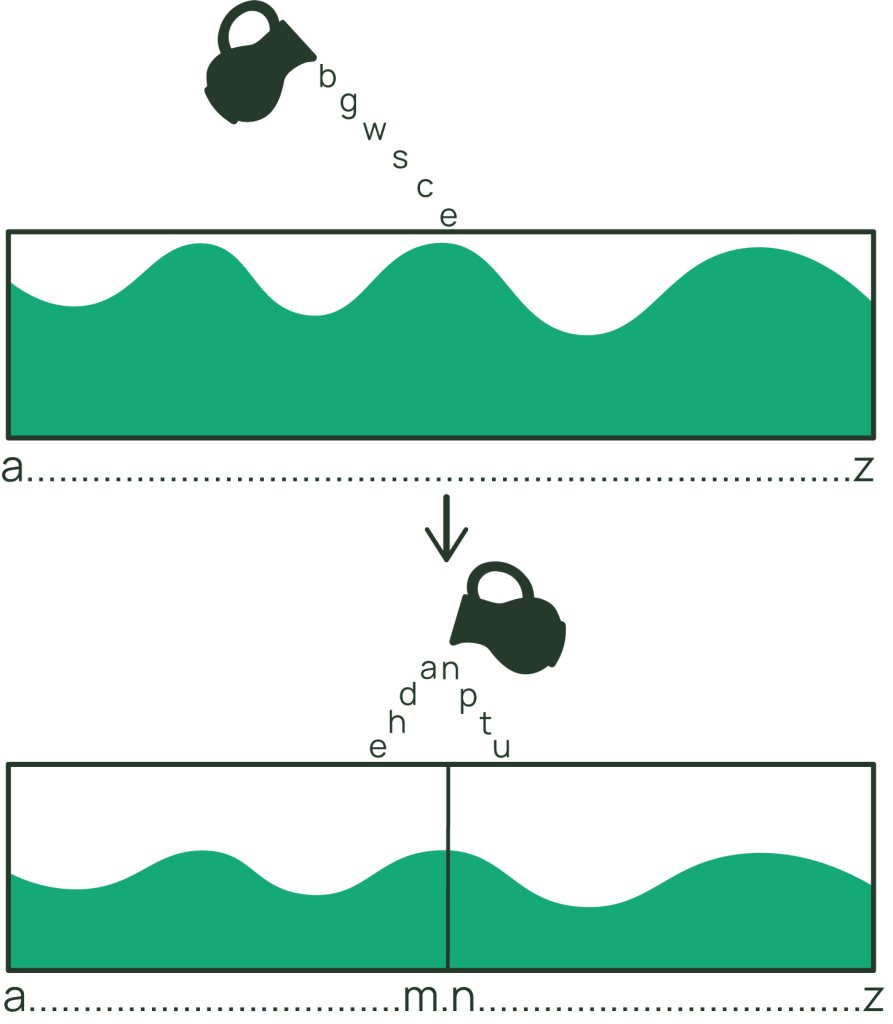
DynamoDBでは、itemとitemコレクションは異なるタイプのレコードであると考えるのが便利です。単純な主キー(ソートキーが定義されていない)を持つ基本テーブルでは、完全にアイテムを扱います。しかし、複合プライマリキー(パーティションキー+ソートキー)を持つテーブルでは、アイテムコレクションを扱います。コレクション内のアイテムは、ソートキーの値順に格納され、正順でも逆順でも返すことができます。
アイテムコレクションは魔法のようなもので、関連するアイテムを一緒に効率的に保存して取り出すことができます。コレクション内のアイテムは、スキーマが異なる場合があります(DynamoDBは柔軟です)。
もし200KBのアイテムがあれば、そのアイテムの小さな部分でも更新すれば、200個の書き込みユニットを消費することになります。その代わりに、そのアイテムがコレクション内のアイテム・パーツのコレクションとして格納されていれば、最小限の書き込みユニット消費で、どんな小さな部分でも更新することができる。しかし、それは始まりに過ぎません!
Queryを使用すると、コレクション内のすべての項目を取得することも、特定の範囲のソートキー値を持つ項目のみを取得することもできます。範囲の指定はソートキー条件と呼ばれます。アイテムコレクションの中で、ソートキーが指定した値より小さいもの、大きいもの、あるいは2つの値の間にあるものに限定することができます。
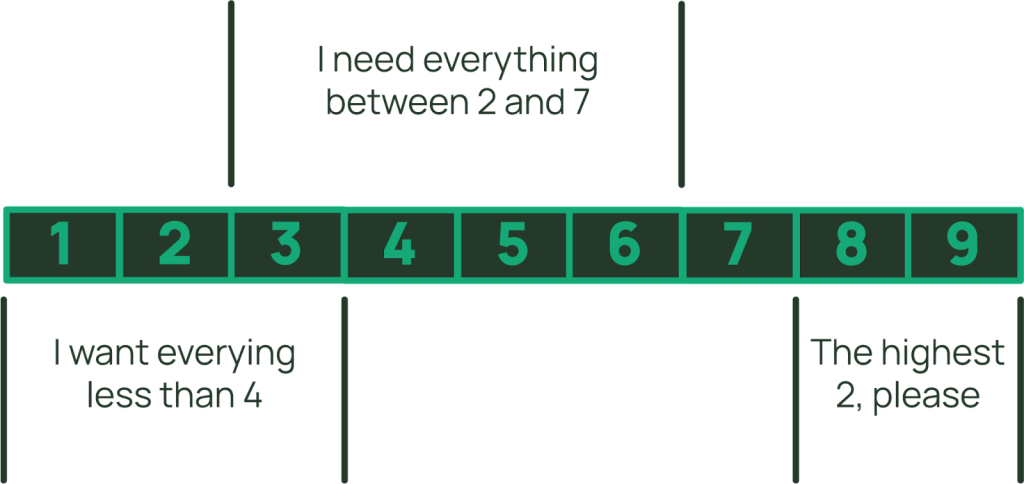
文字列のソートキーの場合、begin_withを使うこともできます(よく考えてみると、これは単なるbetweenのバリエーションです)。ソートキー条件を適用すると、アイテムコレクションから返されるアイテムの範囲が効果的に制限されます。重要なのは、ソート・キー条件に一致するコレクション内のアイテムだけが、読み取り単位の計測に含まれるということです。これは、読み取り単位が評価された後に適用されるフィルタ式とは対照的です。Query(またはScan)を使用して複数のアイテムを取得する場合、読み取り単位の消費量の測定では、すべてのアイテムのサイズが加算され、次の4KB境界に切り上げられます(GetItemやBatchGetItemのようにアイテムごとに切り上げるのではありません)。そのため、アイテム・コレクションを使用すると、非常に大きなレコードを保存し、選択的な部分を低コストで更新し、最適な効率で取り出すことができます。
アイテム・コレクション(Query)とScanは、同じテーブルに2つのアイテムを格納することを主張する、唯一の説得力のあるコストとパフォーマンスの差別化要因です。両者とも、4KB境界に切り上げられたアイテムサイズで複数のアイテムを検索することができます。同じアイテムコレクション(テーブルまたはセカンダリインデックス)に2つのアイテムを一緒にインデックスするつもりがなく、すべてのScanから両方を返したくないのであれば、同じテーブルに保管するメリットはありません。しかし、後で少し説明するデメリットもあります。他のすべてのデータ操作(BatchGetItem、TransactWriteItemsなどのマルチアイテムを含む)では、DynamoDBはアイテムが同じテーブルにあるかどうかを気にしません。
データを同じアイテム・コレクションにまとめるために、プライマリ・キーの値を調整する必要があることがあります。同じテーブルに格納するには、同じ主キー定義を使用する必要があります。この例としては、パーティション・キーやソート・キーのデータ型に合わせて数値を文字列として格納したり、必ずしも格納する重要なものがない場合にソート・キーに一意な値を作成したりします(コレクションに「メタデータ」項目を作成する場合、パーティション・キー属性と同じ値を使用するのが一般的です)。
出荷のために顧客の注文を格納するテーブルを想像してください。パーティションキーは一意な数値の注文識別子(データ型は数値)で、カートの商品ごとのレコード(数値のSKUで識別)と注文処理のための追跡イベント(ksuidのようなソート可能なUUIDで識別)の両方を格納するためにコレクションを使用したいとします。最も一般的なパターンは、トラッキングの詳細に加えて、購入されたアイテムが表示されたトラッキングページを提供することです。この場合、ソートキーのデータ型を文字列で定義し、数値のSKUを文字列として格納するように値を変換する必要があります。これにはコストがかかりますが(数値を文字列として格納すると、より多くのバイトを消費するため)、アイテムコレクションの利点を得るためにはそれだけの価値があります。
アイテムをテーブルに書き込むときに、これらの変更に対応するのは簡単なので、開発者はすべてのアイテムやアイテムコレクションに対応したほうがいいのではないでしょうか?そして、それらをすべて同じテーブルに置くのか?すべてのDynamoDBの顧客が一緒になって、1つの巨大なマルチテナントテーブルにデータを格納することに意味があるのでしょうか?もちろんそうではありません。これらのテクニックにはコストがかかり、アイテムコレクションのメリットを享受するために正当化できる場合にのみ使用されるべきです。
最後に
「シングル・テーブル・デザイン」指導の価値ある有効な部分は、単純にこれだけです:
DynamoDBのスキーマの柔軟性とアイテムコレクションを使用して、必要なアクセスパターンに対してデータモデルを最適化します。リレーショナルデータベースから移行する場合、以前の完全に正規化されたモデルよりもテーブル数が少なくなる可能性が高くなります。おそらく複数のテーブルを持つことになり、セカンダリパターンに対応するために必要なグローバルセカンダリインデックス(GSI)の数を使用する必要があります。
そう、それです。新しい用語を作る必要などなかったのです。「シングル・テーブル・デザイン」は一部の人々を混乱させ、他の多くの人々を苦痛と複雑さ、そしてコストのかかる道へと導いたのです(これについての詳細は次回の記事で)。この用語は、スキーマの柔軟性とアイテム・コレクションに固執することなく、ただ放っておく時なのです。
このトピックについて私と議論したい場合、あなたが持っているDynamoDBデータモデリングに関する質問について私の考えを聞きたい場合、または今後の記事で書くべきトピックを提案したい場合は、Twitter(@pj_naylor)で私に連絡するか、メールをお送りください!
LSIとGSIのニュアンスの違いや、「GSIオーバーローディング」がなぜインチキなモデリングパターンなのかについて説明する続報をお楽しみに。

Share






