さて、「ダークアート」は言い過ぎかもしれませんが、マルチテナントを正しく利用するのは確かに難しい問題です。マルチテナントシステムが提供する効率性を利用したくなる一方で、それはリスクの高い事業でもあります。気をつけないと、分離が損なわれ、貪欲なテナントがシステム内の他のテナントの可用性とパフォーマンスに影響を与えることになりかねません。
最近発表されたDynamoDBの論文は広く取り上げられています(もし論文を読んでいないのであれば、少なくともアレックス・デブリーとMarc Brookerによる素晴らしい要約を読むことをお勧めします)。このブログでは、その隠れた宝石の1つである、DynamoDBのようなミッションクリティカルなサービスがマルチテナンシーをどのように扱うかに焦点を当てています。この論文には、成功するマルチテナントシステムの構築について学ぶべきことがたくさんありますが、まずマルチテナンシーの利点と、うるさい隣人を避けるためのメカニズムを理解することが重要です。
さあ、飛び込もう!
マルチテナントの背景
マルチテナントはイノベーションを促進します。シングル・テナント・システムは通常、小規模で運用されるため、運用者はシステムを維持するために最小限の努力しかありません。マルチテナントシステムの顧客ベースが大きくなるにつれて、共通のパターンが出現し、ユーザーのためにイノベーションを起こすための投資を正当化することが容易になります。例えばDynamoDBでは、これがオンデマンド・プロビジョニングのようなイノベーションを促進し、DynamoDBの各顧客に、プロビジョニングを行うことなくバーストに対処する能力を与えました。
マルチテナントによる経済性の向上
マーク・ブルッカーが一番いいことを言っています:
マルチテナントは経済的にも効率的にも大きなメリットであり、リソースの利用率も高くなる傾向がある。これは持続可能性にとっても良いことだ。また、システムが処理する必要のあるワークロードのダイナミックレンジが小さくなるため、可用性にとっても良いことだ。
もしあなたがマルチテナンシーを信じるようになったら、マルチテナンシーに関するAllen Heltonのブログも読んでみてほしい!そしてTwitterもフォローしてみて下さい。
しかし、マルチテナントはどのように経済性を向上させるのだろうか? まず第一に、シングルテナントシステムは、a) オーバープロビジョニング(高コスト)、b) アンダープロビジョニング(ピーク時に停止するリスク)、またはc) 平均的な負荷に対してオーバープロビジョニングされ、バーストを処理するためのスケーリング能力に欠けています。
マルチテナントシステムでは、リソースは共有プールに統合され、サービスオーナーは利用率を向上させるためにイノベーションを起こします。100個のキャッシュの集合体を考えてみましょう。ピーク負荷の総和は、システム内のすべてのピーク負荷の総和よりも有意に小さいのです。シングル・テナント・キャッシュの集合は、そのピーク負荷を処理するために個別に容量をプロビジョニングします。したがって、プロビジョニングされた容量の合計は、個々のピークを処理するために必要な容量の合計となります。対照的に、マルチテナント・システムは、ピーク総計のために容量をプロビジョニングします。これは、プール内のキャッシュの数が増加するにつれて真実味を帯びてきます。
第二に、大規模なマルチテナント・システムのオペレーターは、毎朝起きて、(高い拡張性と可用性は言うまでもないが)システムをより費用対効果の高いものにする方法について悩みます。コストの最適化には数ヶ月を要することもあり、十分な規模になるまでそれを正当化するのは難しいでしょう。さらに、手作業によるコスト最適化(キャッシュクラスタのスケールダウンなど)は、数千ドルの報酬であれば、取るに値しない(あるいはリスク回避に労力を費やす)運用リスクをもたらす可能性があります。
月額948ドルの3インスタンス(cache.r5.xlarge)のElastiCacheクラスタを運用している顧客を考えてみましょう。このクラスタには26GBのRAM、4つのVCPUがあり、毎秒100K以上のリクエスト(RPS)を簡単に処理できます。もしあなたのチームが5GBのRAMしか使用していない、あるいはピーク負荷が10K RPSしかないことに気づいたら、より小さなインスタンス・サイズへの移行を検討してもよいでしょう。さらに新しいインスタンスタイプ(理想的にはGraviton)に移行することで、さらなる節約とパフォーマンスの向上が可能であることに気づくかもしれません。一方、このクラスタに年間$12Kしか費やしていないのであれば、クラスタのサイズを変更するためにスプリントや運用リスクを割く価値が本当にあるのだろうか?おそらく無理だろう。ほとんどのチームは人員不足であり、もっと簡単にお金を節約する方法があります。
今、年間1200万ドルのコストがかかる3000ノードのクラスタを運用している場合を想像してみてください。小規模インスタンスやGravitonへの移行によるコスト削減を評価するためにエンジニアを割く価値があるだろうか?あるいは、新しいピークに対応するためにフリートサイズを拡張する自動化を構築するか?あるいは、自動化されたデプロイメントのためにシステムを深く計測する必要があるだろうか?もちろんです!
マルチテナント・サービスの運営者は、規模の経済を利用して、システムの効率、規模、可用性を革新します。さらに、十分なスケールとデータがあれば、システムのオーバーサブスクライブを開始し、さらなる効率化を実現することができます。このような現象は、クラウドの世界以外でも常に見られます。銀行から、折衷的なグリッド、そしてあなたのISPまで。
AWS Lambdaを運用しているチームによるFirecrackerの論文では、マルチテナント・サービスとしてLambdaを運用する際のオーバーサブスクリプションの威力を取り上げている:
オーバーサブスクリプションは、基本的に統計的な賭けである……あるコンプライアンス目標X(例えば、99.99%)を設定し、ファンクションがX%の時間、競合することなく、必要なすべてのリソースを得ることができるようにする……これらのワークロードを無相関に保つには、それらが無関係であることが必要である。
DynamoDBはこの統計的な賭けに成功し、アイドル状態のリソースを持つシングルテナントシステムとは根本的に異なる経済性を実現しています:
DynamoDBはマルチテナントアーキテクチャを採用しています。DynamoDBは、異なる顧客のデータを同じ物理マシンに格納することで、リソースの高い利用率を確保し、コスト削減を顧客に還元しています。
マルチテナントシステムはより堅牢なスケーリングが可能
マルチテナント・システムを使用する2つ目の理由は、より優れたスケーリング特性を提供するためです。チームが100ノードクラスタにスケールする際に学ぶことは多くあります。残念なことに、これらの教訓は一度に1つの障害によってもたらされることが現実です。その道のりは、チームにとって謎に満ちています。チームは膨大な量のベンチマーク、計測、特性評価、チューニングを行わなければなりません。
一方、DynamoDBのような大規模なマルチテナントシステムの顧客であれば、100パーティションのDynamoDBテーブルを裏で何百ものノードにまたがって作成するのは初めてではないので安心してください。この一見巨大に見えるスケールも、DynamoDBフリート全体から見れば些細なことです:
DynamoDBは、テーブルの無限のスケールを実現します。各テーブルが格納できるデータ量にあらかじめ定義された制限はありません。テーブルは、顧客のアプリケーションの需要に合わせて弾力的に成長します。DynamoDBは、テーブル専用のリソースを、必要に応じて数台のサーバーから数千台まで拡張できるように設計されています。DynamoDBは、データストレージの量とスループット要件の要求が大きくなるにつれて、アプリケーションのデータをより多くのサーバーに分散します。
あなたがサービスに投じようと考えている規模がどのようなものであれ、それはきっと別の顧客(または顧客の集合体)にとってより大きなものを扱うことになる。
マルチテナントシステムは、スケーリングとプロビジョニングを高速化させる
うまく構築されたマルチテナント・システムは、新規顧客からのバーストや既存顧客からのスパイクに対応するため、ウォーム・プーリングを活用しています。これは、システムがスパイクを吸収するために手元に置いておく余剰容量です。
ウォーム・キャパシティは技術的には非効率の原因ですしかし、システムが大きくなるにつれ(そしてより多くのデータを収集するにつれ)、オペレーターは、リソースを無駄にすることなく素晴らしい顧客体験を提供するために必要なウォームキャパシティの量を調整することができます。実際の例としては、公共バスで見かける空席があります。道路を走るほとんどの車が4席空席のまま走り回っていることに気づくまでは、過剰に感じられます。利用率50%のバスは、道路を走る各車両の過剰キャパシティの合計よりも有意義に効率的です。道路を走っていない車(利用率0%)の座席をすべて組み込むと、これは劇的に面白くなります。ウーバーのイノベーションの多くは、車のエコシステムの利用率向上を中心に展開されています。
利用率50%のバスは、道路を走る各車両の余剰能力の合計よりも有意義に効率的
ウォームプーリングにより、マルチテナントシステムはほぼ即座にプロビジョニングを行うことができます。この最たる例は、Lambda関数が必要なときに即座にオンになることです。何か大規模な、あるいは特別に突発的なことをしない限り、キャパシティを事前にプロビジョニングすることを心配する必要はありません。Lambdaのウォームプールがスパイクを吸収し、リクエストに応じて実行される関数に瞬時にアクセスできます。
これは、ロードバランサーの後ろにオートスケールEC2インスタンスを置くよりも有意義に速くなります。なぜなら、a)スパイクを検出し、b)プロビジョニング不足であることに気づき、c)新しいEC2インスタンスをインスタンス化し、d)起動を待ち、e)ロードバランサーの後ろでそれらをアクティブにし、f)新しい負荷がこれらのインスタンスを襲い始める必要があるからです。このプロセスには数分かかることもあります。これをLambdaと比較すると、Lambdaでは自動化とウォームプーリングがすでに組み込まれており、瞬時のバーストと、これを効率的に行うために必要な適切なオーバーサブスクリプションを実現できます。
マルチテナント・システムは可用性が高い
マルチテナントシステムを使用する最後の理由は、可用性を高めることです。キャッシュの場合、予測可能なパフォーマンスと使用量の急増に対応する能力も可用性の定義に含まれます。これを理解するために、別の交通機関に例えてみましょう。
飛行機が怖いという人はいるかもしれないが、飛行機事故で亡くなるより自動車事故で亡くなる可能性の方がはるかに高いのです。航空会社のようなマルチテナント・サービスの運営者は、航空機を入念に管理し、平均的な車の所有者よりもシステムの健康状態について深い計装を持っています。離着陸(配備に似ている)はリハーサルが行われ、管制塔全体がオペレーションを監督しています。対照的に、多くの個人が自分の車を運転するということは、無数の制御不能な変数を意味します。同様に、自分で管理するデータベースやキャッシュを運用する顧客は、スケールイン/スケールアウトのようなデプロイメントで手探りに終わることが多くあります。
マルチテナントシステムは、よりよく特性化され、限界が公表され、より予測可能な方法で故障する。可用性バイアスのせいで、これらのシステムは可用性が低いと思われがちです。これは単に、これらのシステムが故障の特徴づけや概略の説明をよりよく行っているのに対し、自己管理型システムではより驚くような故障が発生するという事実が原因であることが多くあります。
例えば、DynamoDBでは、1KBのオブジェクト1つに対して1秒間に1,000回の書き込みが可能で、最大オブジェクト・サイズは400KB(これは1秒間に2.5回しか書き込めない)という制限が公表されています。一方、Redisにはそのような制限はなく、1つのキーに対してより高いスループットを得ることができます。ただし、512MBのオブジェクトを保存し始めたり、ホットキーをプッシュし始めたりする場合は、使用範囲が異なるかもしれません。この種のシングル・テナント・サービスでは、サービスがいつ転覆するかわかりません。
DynamoDBは予測可能性を重視しています。DynamoDB論文の図5と図6は、負荷(10万TPSから100万TPS)に関係なく、テールレイテンシが驚くほど似ていることを概説しています。論文発表の際、多くの人がなぜ軸にラベルが付けられていないのか不思議に思いました。答えは簡単で、特定のレイテンシは、スケールに依存しないテールレイテンシ(p99)の一貫したパフォーマンスよりも重要ではないからです。言い換えれば、DynamoDBのクライアント側のパフォーマンスは、負荷が10万、25万、50万、1Mの場合は区別がつきません。
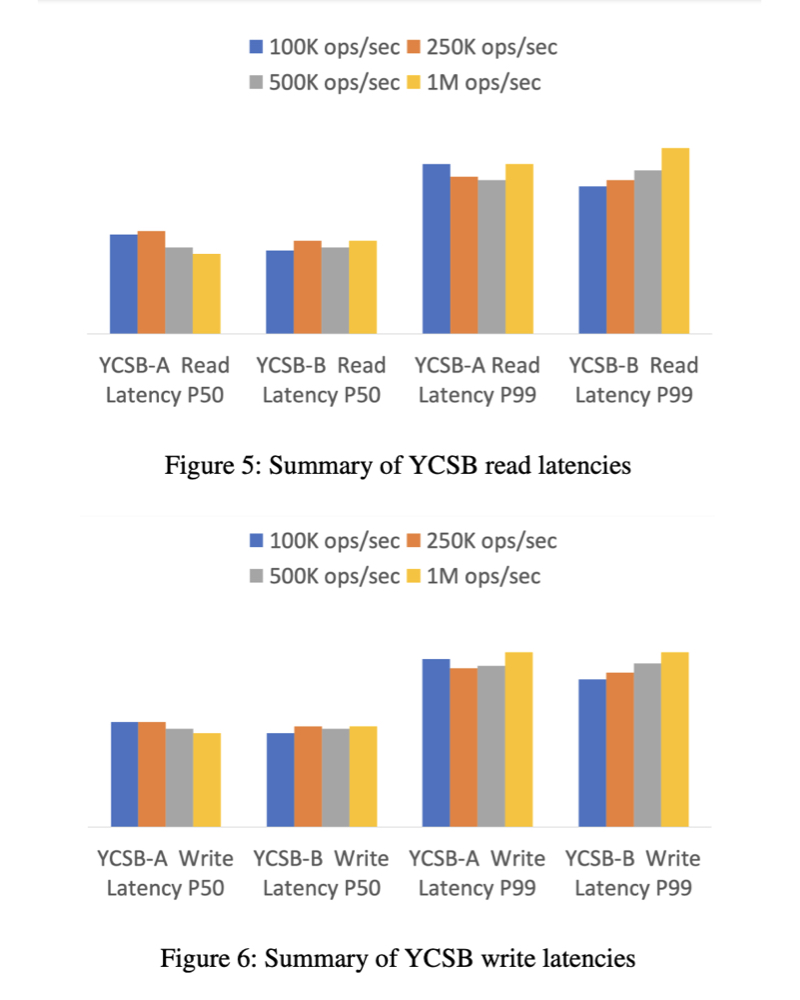
しかし、このテストのマルチテナントの意味を考えるまでは、ばらつきのなさ自体は興味深いものではありません。このテストは、おそらくマルチテナントのDynamoDBプロダクション・フリートに対して実行されました。これは、DynamoDBチームが他のテナントに影響を与えることなく1M TPSを実行できたことを意味し、もちろんその裏返しでもあります。このテストは、エンジニアに相談しなくても、DynamoDB上で自分で再現でき、同じ結果が得られます。
マルチテナント・システムの悩みの種
これで、マルチテナント・システムを求める理由がわかりました。このような利点があるにもかかわらず、なぜもっと普及しないのでしょうか?
その答えは、ノイジー・ネイバー(うるさい隣人)です。貪欲でノイジーな隣人は、システム内の他のテナントのパフォーマンスや可用性に影響を与える代償として、リソースの公平なシェア以上のものを取ってしまう可能性があります。したがって、公平性と優先順位付けは、マルチテナント・システムを成功させるための鍵となります。以下のセクションでは、このトピックに関するDynamoDBの論文を深く掘り下げながら、マルチテナントシステムがこれらのシナリオからどのように身を守るかを説明します。しかしその前に、シングル・テナント・システムも同じようにノイジー・ネイバー問題に悩まされていることを理解する必要があります。
例えば、私は妻の車を借りて長距離ドライブに出かけ、充電や給油を忘れることがある。しかし、午前中にガス欠に気づき、遅刻してでも給油しなければならない。
車内に2つのテナント(私と妻)がいるマルチテナントシステムを説明したことを指摘される前に、次のことを考えてみてください:ElastiCache Redisクラスタではシングルテナントかもしれませんが、クラスタにアクセスできるチームメイト(またはマイクロサービス)がいるかもしれません。1つの不正なマイクロサービスがクラスタ全体に影響を与える可能性があります。あるマイクロサービスがRedisに10MBのオブジェクトを追加し、別のマイクロサービスがスキャンを行っているときに、テールレイテンシーが発生することを想像してみてください。
マルチテナント・システムには、一般的な停電を防ぐために、より深い計装と綿密な手順がある。公共バスには、バスを保守し、十分なガスを確保するために、朝(そして一日中)チェックリストと手順があります。
DynamoDBのマルチテナントをサポートするビルディングブロック
DynamoDBがどのようにマルチテナンシーをサポートするかは、以下のセクションで説明します。可用性はDynamoDBの重要な目標です。これは、どのような規模でも予測可能なレイテンシでリクエストを正常に処理することを含みます。DynamoDBは、分離(顧客同士を保護する)、公平性(システムが危機に瀕しているときに顧客間で優先順位をつける)、リソース管理(十分なキャパシティがあり、それが十分に利用されていることを保証する)を実装する必要があります。
まずはDynamoDBのストレージシステムから見ていきましょう。
DynamoDBテーブルは、DynamoDBストレージノードに存在するパーティションで構成されます。各ストレージノードは、テーブルとアカウントにまたがる多数のパーティションレプリカで構成されます。異なるアカウントのパーティションが同居しているため、DynamoDBはパーティションレベルで分離を維持する必要があります。これを放置すると、1つのパーティションがノードで利用可能なすべてのリソースを消費し、他のパーティション(および顧客)が飢餓状態に陥る可能性があります。
リソースの利用を最適化するための負荷軽減と負荷分散
大規模な分散システム(キャッシュなど)でよくあるテーマに、ホットシャード(一般にホットパーティションとも呼ばれる)という概念があります。これは、分散フリート内の1つのノードが圧倒的な量の負荷を処理している場合に発生します。その結果、一般的なテクニックは、フリートサイズを2倍にして負荷をさらに分散させることです。同様に、分散システムのノード間で負荷が不均等に分散している場合、システムの総サイズはその不均衡に比例して大きくなります。
利用率を向上させるために、DynamoDBはストレージノード間で負荷を分散させることに多大な革新を行ってきました。その方法を理解するために、DynamoDBの中枢であるautoadminサービスについて学ぶことから始めます。論文の概要は以下の通りです:
autoadminサービスは、DynamoDBの中枢神経系として構築されています。フリートヘルス、パーティションヘルス、テーブルのスケーリング、すべてのコントロールプレーン要求の実行を担当します。このサービスは、すべてのパーティションの健全性を継続的に監視し、不健全(遅い、応答しない、不良ハードウェアでホストされている)と判断されたレプリカを置き換えます。
autoadminは、フリート全体の変更を調整します。この一元化により、DynamoDBはフリート全体を継続的に監視できるようになり、同時に、あまりにも多くのノードが決定を下してフィードバックループが発生した場合に発生する可能性のあるフリート内のチャーンを最小限に抑えることができます。
ストレージノードはまた、使用率について自分自身を監視します。ノードが設定可能な閾値を超えたことを検出すると、オートアドミンサービスに通知し、負荷を減らすために移動すべきパーティションのリストを提案します。autoadminはストレージノード全体の利用率を把握しており、リスト内のパーティション(おそらく利用率の低いストレージノード)の新しい住処を見つけます。この継続的な監視により、各パーティションの使用パターンが変化しても、負荷を分散させることができます。DynamoDB論文より:
In case the throughput is beyond a threshold percentage of the maximum capacity of the node, it reports to the autoadmin service a list of candidate partition replicas to move from the current node.
この単純なテクニックは、DynamoDBパーティションがプロビジョニングまたは割り当てられた容量を超えてバーストすることを可能にしますが、過負荷になる危険性のあるストレージノードから負荷を移行することもできます。
公平性は重要だが、孤立と利用はもっと重要
十分な容量と均等に分散された負荷は、公平な経験を自動的にもたらします。公平性が発揮されるのは、主にシステムが切迫しているときです。DynamoDBストレージノードは、利用可能な十分な容量がある限り、リクエストに対応します。このオーバーサブスクリプションによって、DynamoDBは、プロビジョニングされたIOPSを持つ顧客だけでなく、オンデマンドで実行されている顧客全体の利用率を向上させることができます。
このアプローチは単独では機能せず、複数のメカニズム(制御バースト、優先順位付け、スロットリング)によって補完されます。まず、制御されたバーストによって、1つのパーティションがノード上で消費できる最大IOPSが制限されます。これにより、ノード上でのパーティションの爆発半径が小さくなり、DynamoDBチームにとってより効果的なキャパシティ・プランニングが可能になります。
第 2 に、バーストは、未使用の容量を持つノードにたまたま配置されたパーティションでのみ使用できます。論文では次のように言及されています。
DynamoDB は、ノード レベルで未使用のスループットがある場合にのみパーティションがバーストできるようにすることで、ワークロードの分離を維持しました。
DynamoDB には 2 種類のテーブル (プロビジョニングされたテーブルとオンデマンド) があります。プロビジョニングされたテーブルでは、IOPS はパーティション間で分散されます。ただし、システムでは、必要に応じて、これらのパーティションがプロビジョニングされた IOPS を超えてバーストすることが許可されています。 DynamoDB オンデマンド テーブルは顧客のワークロードに迅速に適応し、顧客によるキャパシティ管理を不要にします。これらは EC2 スポット インスタンスに似ていますが、厳密な容量管理と負荷分散により、DynamoDB チームはオンデマンド テーブルに対してほとんど区別できないエクスペリエンスを提供できます。
DynamoDB はリクエストに優先順位を付けて、最大限の利用と分離を実現します。たとえば、ストレージ ノードが圧迫されている場合、公平性を課すことが重要になります。ノード上でプロビジョニングされた IOPS を持つパーティションは、その上でバーストしているパーティションよりも優先されます。前述のプロアクティブな負荷制限を考慮すると、これは通常、一時的な現象です。負荷を分散するために、強制状態にあるストレージ ノードはすぐに自動管理と連携します。一方、ノードの使用率が低い場合、各パーティションは、プロビジョニングされた IOPS に関係なく、しきい値 (3,000 IOPS) までバーストする能力を持ちます。チームは、SLO を満たすためにこの統計的賭けを最適化するために懸命に取り組んでいます (使用率が増加すると、ノイズの多い近隣の影響が発生しやすくなりますが、使用率が減少すると効率が低下します)。また、ほとんどの顧客は変動に気付かないため、チームは分離にかなり成功しています。
グローバル アドミッション コントロール (GAC) によるスロットリング
初期の頃、DynamoDB はストレージ ノードのパーティション レベルで IOPS 制限を課していました。これは、IOPS がすべてのパーティションにわたって適切に分散されていない顧客にとって、かなりひどい副作用をもたらしました。このような状況では、お客様は、プロビジョニングされた IOPS の小さなパーティションを利用しているにもかかわらず、テーブルでスロットリングが発生することになります。
DynamoDB は、グローバル アドミッション コントロール (GAC) の概念を使用して、この分野で革新をもたらしました。これにより、IOPS をパーティションではなくテーブル レベルで適用できるようになります。
DynamoDB リクエストは、関連するストレージ ノードにオペレーションを転送するステートレス リクエスト ルーター層を通過します。これらのリクエスト ルーターは、各テーブルに割り当てられた IOPS の数を知っています。これらは GAC ノードのフリートに接続し、割り当てられたテーブルのトークン バケットを追跡します。このようにして、過剰な容量を消費するテーブルは、リクエストがストレージ ノードに到達する前にリクエスト ルーターで調整される可能性があります。
ストレージ ノード トークン バケットは、多層防御のために保持されています。これらは、リクエスト ルータがノードで処理できる量を超えるリクエストを受け入れた場合でも、ストレージ ノードがパーティションを分離し、バーストしきい値を下回るパーティションに優先順位を付けることができるようにするための第 2 層として機能します。
最終的な考察
DynamoDB は、マルチテナントがどのようにイノベーションを促進するかを示す最良の例の 1 つです。ミッションクリティカルな可用性を備えたマルチテナンシーを大規模に適用できるようにするには、チームが使用率、コストの最適化、パフォーマンスの革新を行う必要がありました。顧客は分散システムの専門家にならずにこれらすべてのメリットを享受でき、その下でシステムは進化し続けました。
DynamoDB は、負荷制限、ノード レベルとテーブル レベルでのスロットル、ベスト エフォート ベースでのバースト処理に関する補完的なメカニズムを通じてマルチテナントを処理します。これらのシステムはどれも単独では十分ではありませんが、これらを組み合わせることで、Amazon の小売店、ほとんどの AWS コントロール プレーン、そして結果としてほとんどの AWS 顧客にとって、非常に信頼性の高いミッションクリティカルなサービスを構築できます。
マルチテナント システムは、シングルテナント システムよりも可用性が高く、基本的に経済性が優れており、優れたエクスペリエンスを提供します。一方、多くのシングルテナント システムは、よく構築されたマルチテナント システムが明示的に顧客を保護するのと同じノイジー ネイバーの問題の影響を受けやすいことがよくあります。
Momento ではマルチテナンシーを心から受け入れており、それがイノベーションを促進しています。当社はすでに、リソースとパフォーマンスの最適化への多大な投資に見合う規模で事業を行っており、お客様に喜んでいただけるようこの道を継続していきたいと考えています。
ご質問、私の記事の修正、フォローアップトピックの提案などがございましたら、私 (@ksshams) にツイートしてください。

Share





