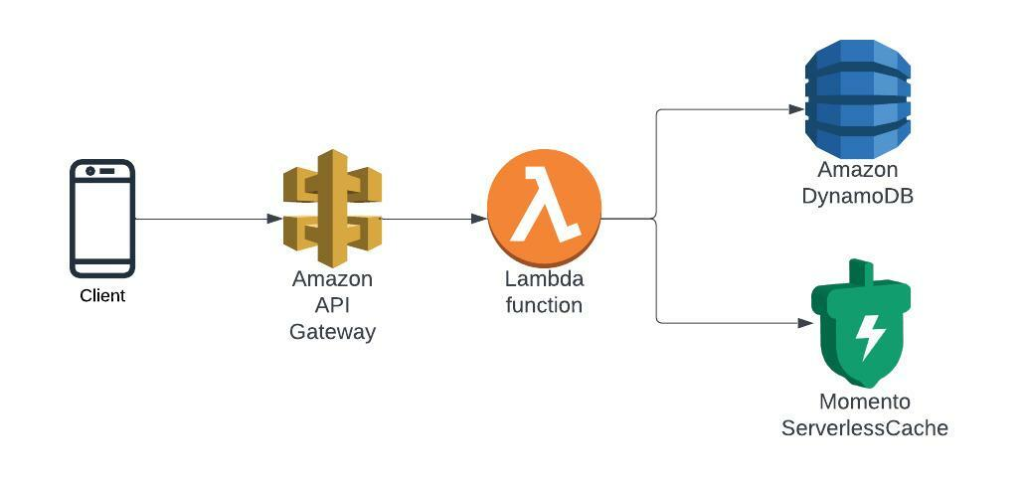
サーバーレスは開発者の生産性を飛躍的に向上させました。サーバーレスの従量課金モデルは、コスト削減と同時にキャパシティ管理の負担を軽減します。全体として、サーバーレスによって、開発者は細かな運用の細部で車輪の再発明をする代わりに、コアビジネスに集中することができます。
しかし、サーバーレスには難問があります。原始的なサーバーレス・スタックをキャッシュで加速させようとすると、すぐにサーバーフルにならざるを得ません。キャッシュ・フリート構築は骨の折れる作業です(CBS Sportsが経験したキャッシュ・フリート構築の痛みについてはこちら)。サーバーレス・キャッシングはこれを変え、可用性、弾力性、スケールを向上させます。
もちろん、ローカルにキャッシュすることもできますが、ローカルキャッシュは、何百ものリクエストを同時に処理する従来のサーバーと異なりLambdaでは有効ではありません。一方、従来の常識では、DynamoDBは非常に高速なのでキャッシュは必要ないとされています!
直感的に、キャッシュはDynamoDBよりも速いはずだとわかっていましたが、私はそれを証明したかったのです。アプリケーションをビルドした後、新しいLambdasのデプロイを含め、Momentoでスーパーチャージするのに1時間もかかりませんでした!
あなたも1時間以内に試すことができます。この例は、SAM cliでビルドしてデプロイできるサーバーレスアプリケーションを含む、ハンズオンチュートリアル付きのデモレポで完全にオープンソース化されています。このレポには、Locustを使ってラップトップから小規模な合成テストトラフィックを駆動してサービスをテストする、シンプルなベンチマークスクリプトも含まれています。DynamoDBを使った基本的なサーバーレスタイプスクリプトのREST APIから始め、キャッシュとしてMomentoを使って最適化します。CloudWatchにメトリクスを送信し、CloudWatchダッシュボードで結果を確認できます。
Scenario
各ユーザーがフォロワーを持つソーシャルネットワークを構築しているとします。あなたのフロントエンドアプリは、現在のユーザーの各フォロワーの名前をダウンロードして、デバイス上でレンダリングする必要があります。ユーザーモデルは次のようになります:
interface User {
id: string,
name: string,
followers: Array<string>,
}APIは基本的なユーザーAPIをモデル化しています。LambdaアプリケーションはこれらのCloudWatchメトリクスを生成し、あなたが調べたり対照したりできるようにします。
- Momento: momento-get, momento-getfollowers
- DynamoDB: ddb-get, ddb-getfollowers
/bootstrap-usersエンドポイントを使用して、それぞれ5人のランダムなフォロワーを持つ100人のテスト・ユーザーを生成しました。その後、2つのエンドポイントを公開しました:
GET /users and /cached-users
DynamoDB(/users)またはMomento(/cached-users)を1回呼び出します。
{
"id": "1",
"followers": [
"26",
"65",
"49",
"25",
"6"
],
"name": "Lazy Lion"
}(ところで、JSONを扱うのにjqを愛用しています)
また、(キャッシュの有無にかかわらず)ユーザーのフォロワーを取得するエンドポイントも公開しました:
GET /followers and /cached-followers
渡されたユーザーIDに対して、DynamoDB (/followers)またはMomento (/cached-followers)のどちらかに1回コールし、さらにDynamoDBまたはMomentoのどちらかにN回(このテストでは5回)コールして、各フォロワー名を検索します。
[
"Angry Fish",
"Lazy Otter",
"Angry Sloth",
"Clingy Sloth",
"Dumb Lion"
]
このルックアサイド・キャッシュを実装するために必要なコードは、極めてシンプルなものでした。ここで見ることができます。まずMomentoで値が存在するかどうかを確認し、存在しない場合は次のリクエストのためにDynamoDBからフェッチして保存します。
const getCachedUser = async(userId: string): Promise => {
let user = await getUserMomento(userId)
if (!user) {
console.log("no user found in momento fetching from DDB")
user = await getUserDDB(userId)
// Set item in cache so next time can get faster
await momento.set("momento-demo-users", userId, JSON.stringify(user))
}
return user
}
const getUserDDB = async (id: string) => {
const dbRsp = await ddbClient.send(new GetCommand({Key: {id}, TableName: "momento-demo-users"}));
return dbRsp.Item as User
};
const getUserMomento = async (id: string) => {
const rsp = await momento.get("momento-demo-users", id)
const user = rsp.text()
if (user == null) {
return null
}
return JSON.parse(user)
};結果
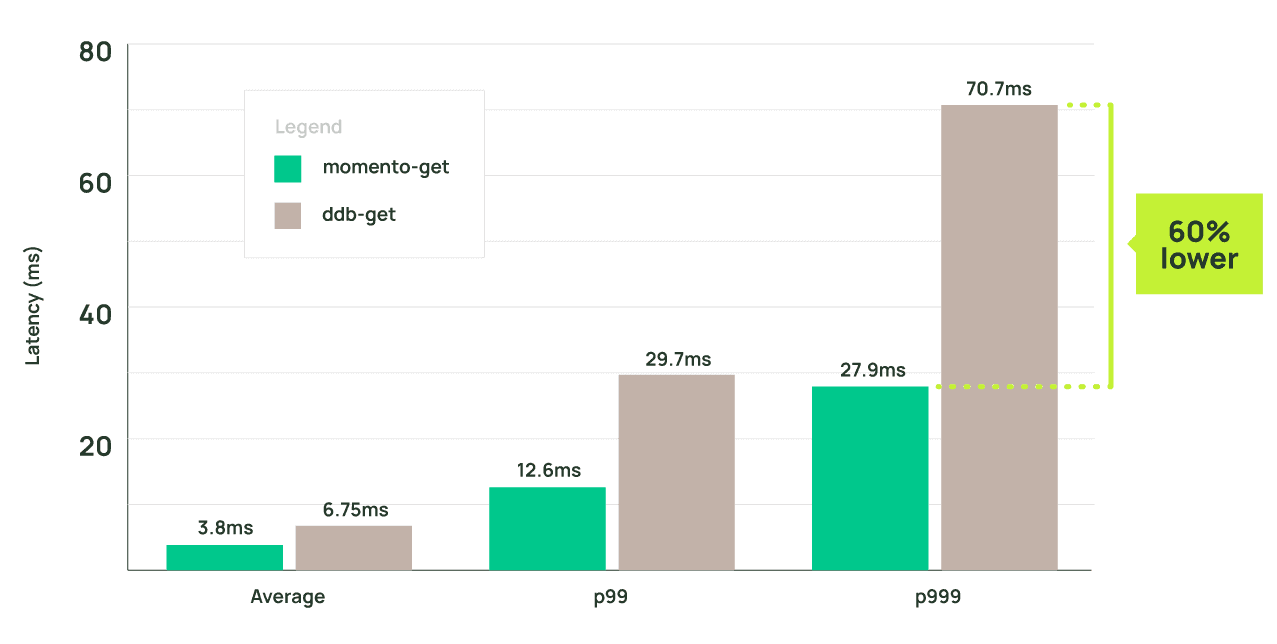
クライアント側の平均待ち時間を厳密に見ると、get-usersの平均待ち時間を~43%短縮(6.75msから3.8msへ)。p99については、~57%(12.6ms vs 29.7ms)の削減、p999については、60%(70.7ms vs 27.9ms)の削減が見られました。
複数のDynamoDBコールを必要とするLambdaでは、さらに興味深いことがわかります。クライアント側の平均的なレイテンシでも、53%程度の低下が見られます(16.5 ms vs 7.61 ms)。p99では、レイテンシは72%低下しています(72 ms vs 19.5 ms)。最終的に、p999では、DynamoDBに対して86%レスポンスタイムを短縮することができました(536 ms vs 72.3 ms)。
学んだこと
1時間足らずの作業で、Momentoはp999のレイテンシを86%以上低下させました。これは、Lambdaのコストが下がり、ユーザーが幸せになり、DynamoDBのホットキーやホットパーティションに悩まされることなく、よりスケーラブルなシステムになることを意味します。LambdaへのMomentoエンドポイントの追加も高速でした!DynamoDBでバックアップされたLambdaをセットアップした後、各Momentoエンドポイントを追加するのに、キャッシュの作成、ルックアサイドキャッシュパターンをサポートするためのLambdaの更新、デプロイを含めて5分もかかりませんでした。第三に、テールレイテンシーが重要です。DynamoDBへの複数の呼び出しが行われるため、Lambdaの平均レイテンシでさえ、DynamoDB呼び出しのテールレイテンシに偏り始めることが早い段階でわかります。
私たちが主催する、このエクササイズを実際に体験できる無料のワークショップにご期待ください。それまでは、私たちのDiscordに参加して、質問に答えたり、あなたの考えを聞いたりしましょう。

Share






