DynamoDB Data Modeling Series
1.DynamoDBのデータモデリングで本当に重要なことは?
2.DynamoDBのセカンダリインデックスはどれを選ぶべきか?(YOU ARE HERE)
3.最適化されたDynamoDBセカンダリインデックスでコスト削減とスケーラビリティを最大化する
4.DynamoDBのシングルテーブル設計の現実
これは、DynamoDBのデータモデリング(「単一テーブル設計」の誤解を除いたもの)についての短いシリーズの2番目の記事です。最初の記事をまだ読んでいない方は、ぜひご覧ください。この記事では、DynamoDBのモデリングで最も重要な概念であるスキーマの柔軟性とアイテムのコレクションについて説明します。今回は、その基礎の上に立って、私のお気に入りのDynamoDBの機能の1つであるセカンダリインデックスについて説明します。この記事では、パーティション、アイテム、プライマリキー型、データ型など、DynamoDBのコアとなる概念をある程度理解していることを前提としています。もし、あなたがそれらのスピードアップが必要なら、お勧めのビデオ・プレイリストはこちらです。
セカンダリインデックスは強力です!セカンダリ・インデックスを使用すると、テーブル内のデータの読み取りに対して自動的に異なる視点を提供することができます。セカンダリインデックスは、同じデータ内で追加のリレーションシップ(項目コレクション)を定義して維持するのに役立ち、関連データを別の次元でソートでき、非常に効果的なフィルタになります。
しかし、他のツールと同じように、DynamoDBのセカンダリインデックスをうまく使えない可能性があります。
大きな力には大きな責任が伴い、選択肢を理解する必要があります!このブログでは、異なるタイプのセカンダリインデックスを比較し、その中から選択するためのヒントを提供することに焦点を当てます。さらに、DynamoDBグローバルセカンダリインデックスの最近の傾向である “オーバーロード “と呼ばれる使用方法と、大部分の設計でそれを避けるべき理由についての考察も加えます。
だから期待していてください!そして、帽子をしっかり持っていてください。旋風的なツアーになりそます。
セカンダリー・インデックスはどこにあるのか?また、どのようにしてそこにたどり着くのでしょうか?
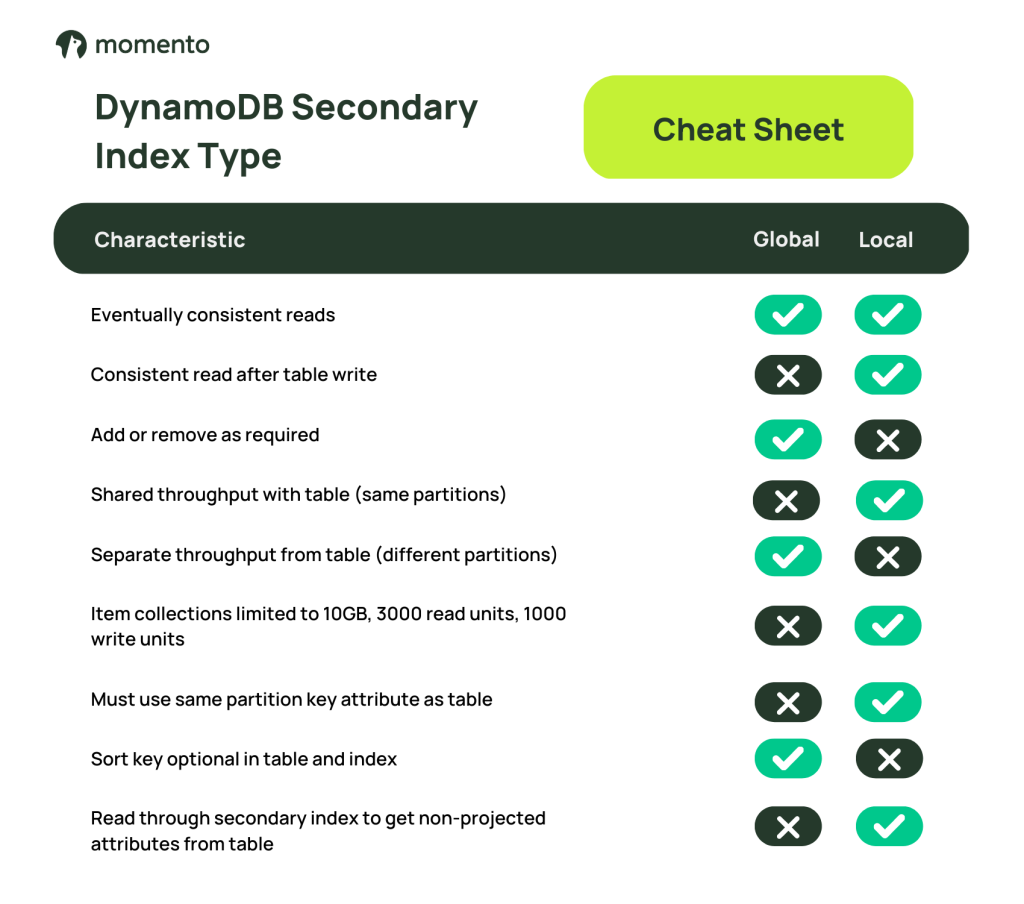
テーブル(プライマリインデックス)のデータは、DynamoDBサービスによって、提供されたインデックス定義に基づいてセカンダリインデックスに投影されます。セカンダリインデックスに直接書き込むことはできませんが、ベーステーブルの項目に書き込むと、DynamoDBが関連する変更をセカンダリインデックスに投影してくれます。セカンダリインデックスには2つのタイプがあります: ローカルセカンダリインデックス(LSI)とグローバルセカンダリインデックス(GSI)です。
Local secondary indexes
LSIは、ベーステーブルと同じDynamoDBパーティション上に存在し、同じパーティションキー属性を共有し(ただし、ソートキー属性は異なる)、ベーステーブルとスループットを共有します。LSIは、同じパーティション内のアイテムコレクションに対して異なるソート順序を提供するため、ローカルです。LSIは、リクエストのパラメータとして指定された場合、ベーステーブルへの書き込み後の強い一貫性のある読み取りをサポートします(そうでない場合は、デフォルトの最終的な一貫性が使用されます)。
実際、LSIとベース・テーブルは同じアイテム・コレクションを共有し、各アイテム・コレクションが単一のパーティションに存在することを制約します。テーブルが1つ以上のLSIを持つ場合、各アイテムコレクションは10GB(ベーステーブルとすべてのLSIのパーティションキー値が同じ値のすべてのデータ)を超えて大きくなることはありません。任意のアイテムコレクションの読み取りと書き込みのスループットは、テーブルと関連するすべてのLSI内で、1秒あたり3,000個の読み取りユニットと1,000個の書き込みユニットに制限されています。
LSIはテーブルの作成時に定義する必要があり、関連するベース・テーブルを削除しない限り削除できません。データモデルでLSIを使用する前によく考えてください。十分な理由(強く一貫性のある読み取りに対する有効な要件など)があり、10GB以上、毎秒3,000個の読み取りユニット、毎秒1,000個の書き込みユニットを必要とするようなアイテム・コレクションを持つことは決してないことを知っていなければなりません。
後でLSIのプロパティに制約されたくない、あるいは特定のLSIはもう必要ないと判断した場合、既存のテーブルから代替のテーブルへの複雑な移行が必要になることがあります。
Global secondary indexes
GSIは独立したテーブルのようなもので、異なるパーティション・キー属性を持つことができ、独自のパーティションとスループット能力を持ちます。必要に応じて(バックフィルで)追加し、不要になったら(コストをかけずに)削除できます。GSIはグローバルであり、ベース・テーブルのすべてのパーティションで、アイテム間の新しい関係(アイテム・コレクション)を定義することができます。GSIのアイテム・コレクションはパーティションにまたがって、より多くのデータを格納し、より大きなスループットを提供することができます(LSIがない限り、ベース・テーブルにも当てはまります)。
LSIとGSIの最大の違いの1つは、ベース・テーブルへの書き込み時の動作です。ベース・テーブルとLSIは同じパーティションを共有しているため、LSIの更新はベース・テーブル項目の変更と同時にアトミックに処理されます。GSIの場合、変更は非同期に別のパーティションに伝搬されます。これには、リード・アフター・ライト一貫性の影響があります。LSIからの読み出しは、必要であれば一貫性を保つように要求できますが、GSIからの読み出しは常に最終的に一貫性が保たれます。
GSIからのリードについてさらに考慮しなければならないのは、単調性です。GSIからの読み取りは単調ではありません。ベース・テーブルの項目を更新して属性の値を 7 から 8 に増やした場合、GSI で投影されたデータを 3 回連続して読み取ると、最初に値が 8 になり、次に 7 になり、最後に 8 に戻ります。GSIの同じデータに対する一連の読み取りは、時間の経過とともに前方にも後方にも移動する結果を返すことができます。テーブルまたはLSIからの一貫性の強い読み取りは単調です。
GSIはLSIよりも柔軟性が高く、どのようなLSIも簡単にGSIとしてモデル化できます。LSIを使用するのは、インデックスが一貫した/単調な読み取りをサポートする必要があると確信している場合、または「リード・スルー」機能の恩恵を受けたい場合のみです(これに関する詳細は、今後のブログで紹介する)。
セカンダリ・インデックス・キーの興味深い性質
まず第一に、インデックス・キーの値は、ベース・テーブルのプライマリ・キーのように一意であるとは保証されていません。インデックスは、インデックス・パーティション・キーとソート・キーに同じ値を持つ複数の投影項目を持つことができます!GetItem APIはセカンダリインデックスではサポートされていません。 なぜなら、GetItemはキーの特定の値に対して最大1つの項目を読み取ることを意味するからです。しかし、セカンダリインデックスでは、インデックスキーの特定の値が提供された場合でも、多くの項目が返される可能性があります!LSIやGSIから読み出すには、QueryかScanを使用しなければなりません。LSIは代替ソートを提供し、GSIは代替コレクションと(オプションの)ソートを提供します。
前述したように、LSIはコンポジット・キーを持たなければなりません。LSIがアタッチされるベース・テーブルもコンポジット・キーを持たなければなりません。LSIのパーティション・キーはベース・テーブルと同じでなければならず、ソート・キー属性はテーブルの属性とは異なっていなければなりません。単純な例としては、表形式でエントリーをリストするグラフィカル・ユーザー・インターフェイスがあるとします。エントリーはグループ化され(パーティション・キー属性の同じ値によって関連付けられたアイテムのコレクション)、列の値の1つ(ベース・テーブルのソート・キー)によってソートされます。もしユーザーが同じグループの項目を別のカラムでソートする必要があるとしたらどうでしょうか?ここでLSIが役に立ちます。
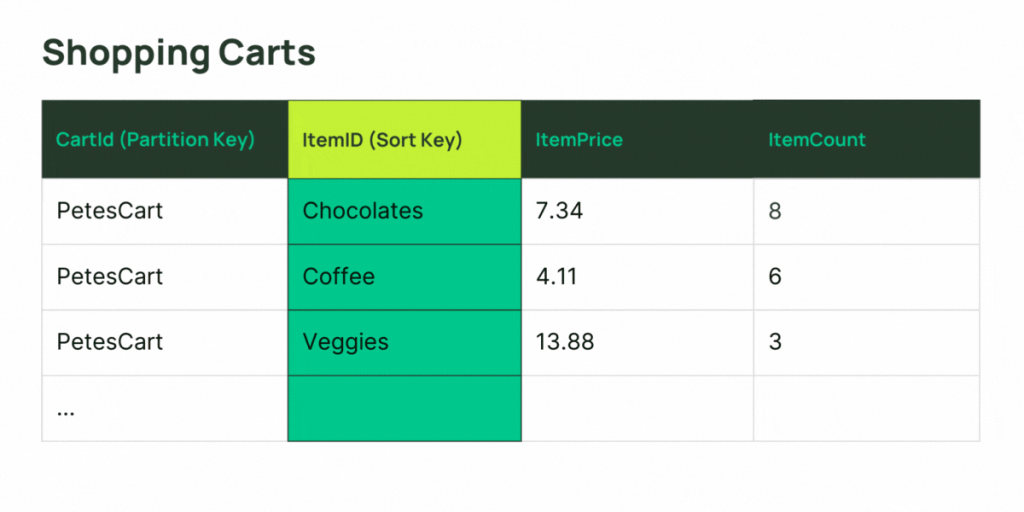
GSIはより柔軟です。パーティション・キーが必要ですが、ベース・テーブルとは異なる属性にすることができます!GSIは、単純なキーまたは複合キーを持つことができます。GSIからアイテムのコレクションをソートされた順序で取得する必要がない場合(おそらく、インデックス内のパーティション・キーに共通の値を持つすべてのアイテムをクエリするパターン)、ソート・キーを定義しないでください。必要ないのにソートキーを定義すると、アイテムのコレクションのスケーラビリティが制限される可能性があります。
セカンダリー・インデックス・タイプの区別を明確にする
ニュアンスはいろいろあるが、結局は単純な違いに帰結します。
このDynamoDBデータモデリング・シリーズ(「単一テーブル設計」を否定することが目的)の次のエントリにご期待ください。今後の記事では、セカンダリインデックスの詳細と、”シングルテーブル設計 “がひどく間違っている点についての総括的な議論を予定しています。
このトピックについて私と議論したい場合、あなたが持っているDynamoDBデータモデリングに関する質問について私の考えを聞きたい場合、または今後の記事で書くべきトピックを提案したい場合は、Twitter(@pj_naylor

Share






