What really matters in DynamoDB data modeling?
Spoiler: it’s not really about the number of tables.

Share
DynamoDB Data Modeling Series
- What really matters in DynamoDB data modeling? (YOU ARE HERE)
- Which flavor of DynamoDB secondary index should you pick?
- Maximize cost savings and scalability with an optimized DynamoDB secondary index
- Single table design for DynamoDB: The reality
When I left the DynamoDB team a couple of months ago, I decided that I needed to share what I’ve learned about designing for DynamoDB and operating it well. Through my six years of working with internal and external DynamoDB customers at AWS, I was fortunate to gain exposure to a wide variety of DynamoDB data models. I’ve also seen the way they evolved in operation: how they scaled (or didn’t) under varying load, their flexibility to accommodate new application requirements, and whether they became cost-prohibitive over time.
This is part one of a short series of articles I’ll publish aimed at correcting some misconceptions about DynamoDB data modeling best practices. In recent years, strange recommendations have evolved through the rumblings of social media (with help from AWS marketing). I’m going to write about the real world. I’ll provide all the same advice the DynamoDB team gives to other Amazon teams for whom the service is mission critical—the same optimization recommendations, the same warnings about “single table” snake oil, the same tips on interpreting metrics, the same detail on metering nuances, and the same operational excellence focus.
Ready to get started? In this first installment, I’m going to set the foundation for the series by sharing the secret sauce to success with DynamoDB. Admittedly, it took me a while to truly grok this stuff. Follow me! I know some shortcuts.
What really matters if it’s not all about the number of tables?
The first two concepts you need to understand when you are learning to take DynamoDB data modeling beyond the simplest key-value use cases are 1) schema flexibility and 2) item collections.
Schema flexibility means that the items in a DynamoDB table do not all require the same structure—each item can have its own set of attributes and data types—this opens up many possibilities! In fact, the only attributes for which the schema is enforced are primary key attributes—those used to index the data in the table. Each item must include the key attributes defined for the table with the correct data type.
An item collection is the set of all items which have the same partition key attribute value; in other words, they are all related by the partition key’s value. If you’re familiar with relational databases, one way to think about this is to look at an item collection as being a bit like a materialized JOIN, where the common value of the partition key attribute is something like a foreign key. To optimize your DynamoDB data model, you want to look for opportunities to use item collections in the base table or in secondary indexes where you have related items that you’d like to (selectively) retrieve together. This might seem obvious, but it’s worth being clear: to be in the same item collection, items also need to be in the same table—the item collection is a subset of the table.
For example, you might represent a shopping cart as an item collection, where the unique cart identifier (Pete’s Cart) is the partition key value, and the identifier for each product added to the cart is the sort key value. Apparently, Pete likes coffee more than veggies, but not as much as chocolates. The number of each product type in the cart is another (non-key) attribute. The image below depicts such an item collection.

Your code has a more rigid definition—like the NoSQL Workbench screenshot below.
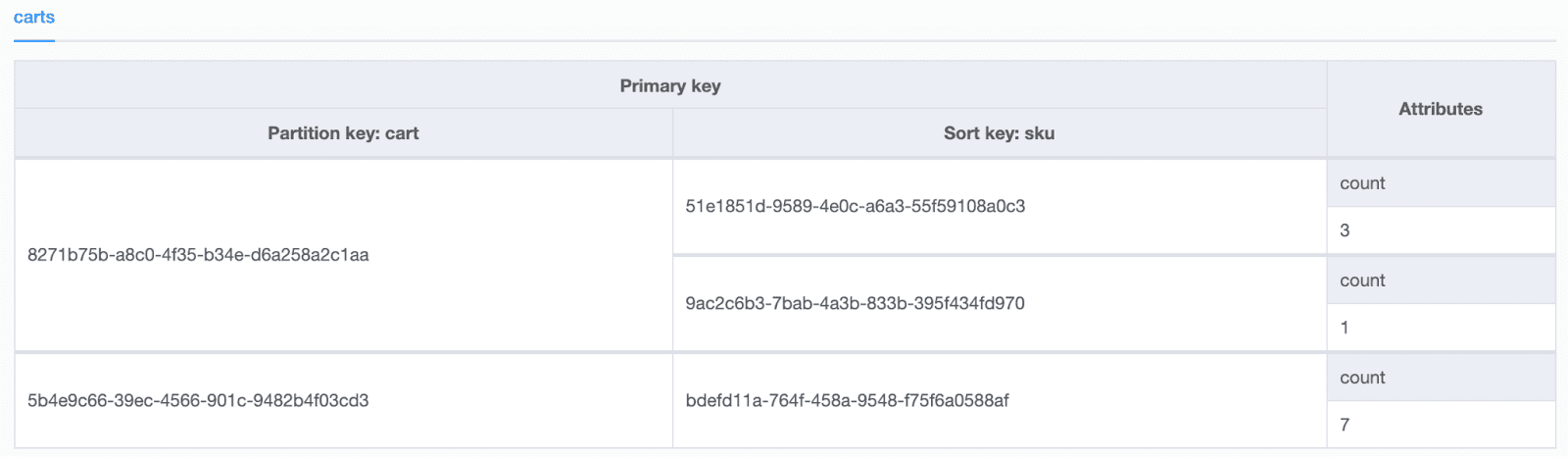
Item collections can exist in the primary index (the base table) and/or a secondary index. I’ll dig into the details of secondary indexes in a future blog, so let’s focus on the base table this time. Item collections in the base table require a composite primary key (partition key and sort key). If there are no Local Secondary Indexes (LSIs), the item collection can span multiple DynamoDB partitions—it won’t start out that way, but DynamoDB will automatically split out the item collection across partitions in order to accommodate growing data volume, and sometimes it can also distribute the item collection across partitions in order to provide more overall throughput or to isolate hotter items (or ranges of items).
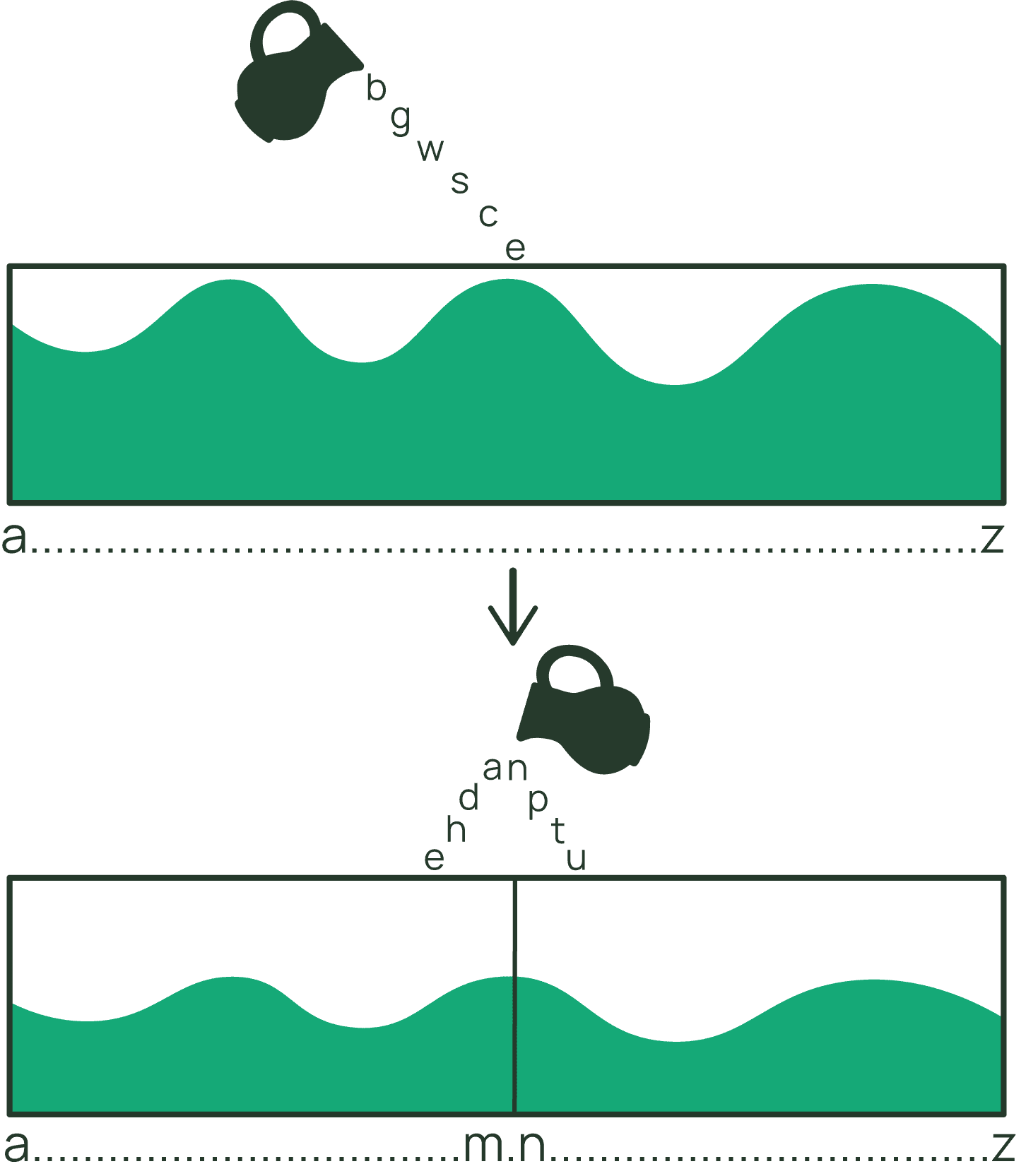
It’s helpful to think about items and item collections as being two different types of records in DynamoDB. In a base table with a simple primary key (no sort key defined), you work entirely with items. But if your table has a composite primary key (partition key + sort key), you work with item collections. The items in the collection are stored in order of the sort key values and can be returned in either forward or reverse order.
An item collection is magical—it allows us to efficiently store and retrieve related items together. The items in the collection might have differing schema (DynamoDB is flexible, remember?)—each representing a part of the overall item collection record.
If you have a 200KB item, then updating even a small part of that item will consume 200 write units. If that item is instead stored as a collection of item parts in a collection, you can update any small portion for minimal write unit consumption. But that’s just the beginning!
You can use Query to retrieve all the items in the collection, or only those with a specific range of sort key values. The specification for the range is called a sort key condition. Within the item collection you can limit items retrieved to be those with a sort key less than a chosen value, or greater than, or even between two values.
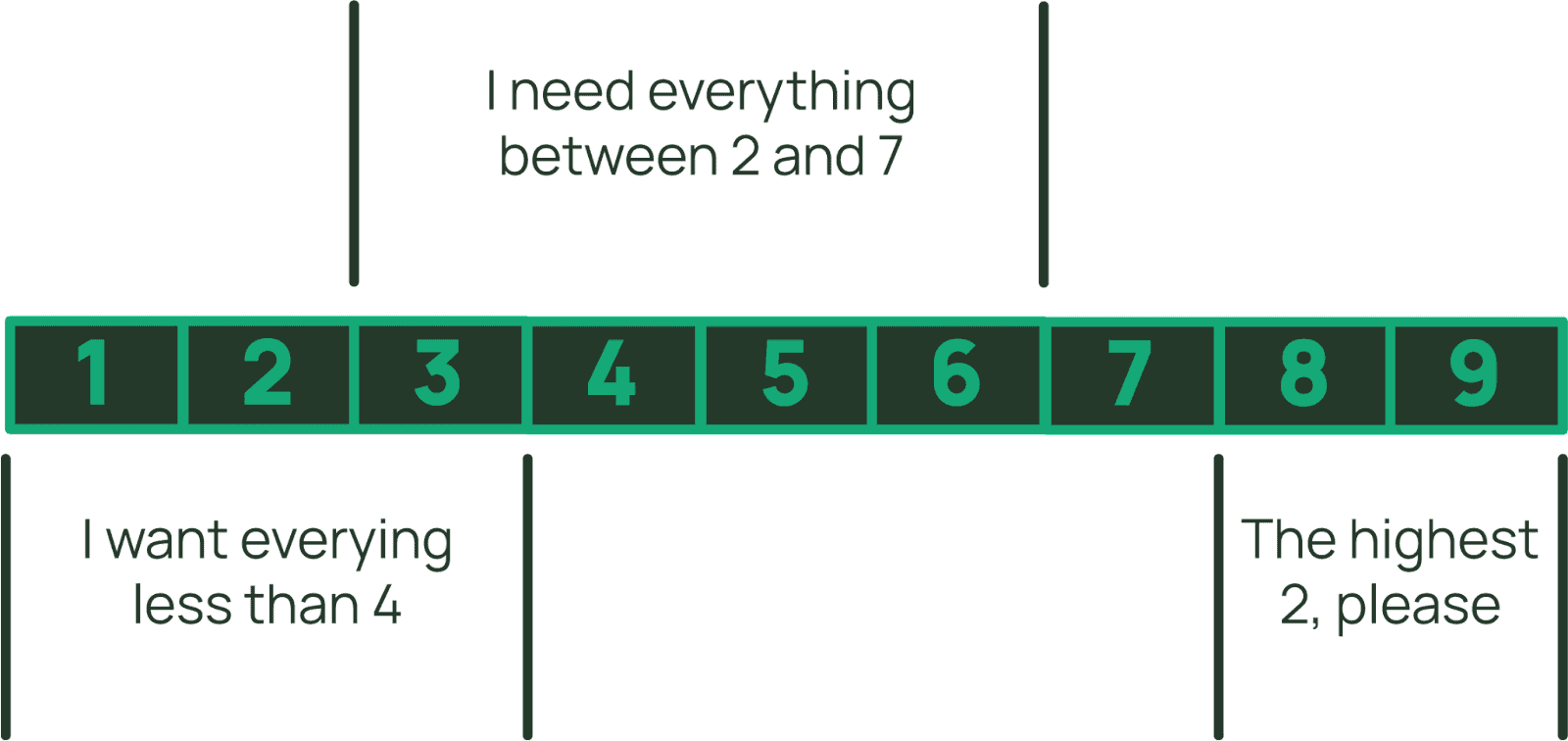
For string sort keys, you can also use begins_with (which is really just a variation of between if you think about it). Applying a sort key condition effectively limits the range of items to be returned from the item collection. Importantly, only items in the collection which match the sort key condition will be included in the metering of read units. This is in contrast with a filter expression which applies after the read units have been assessed—so you still pay to read items which are filtered out. When you retrieve multiple items using Query (or Scan), the metering of read unit consumption adds the sizes of all the items and *then* rounds up to the next 4KB boundary (rather than rounding up for each item like GetItem and BatchGetItem do). So, item collections allow you to store very large records, update selective parts at low cost, and retrieve them with optimal efficiency.
Item collections (Query) and Scan are actually the only compelling cost and performance differentiators that argue for storing two items in the same table. They both allow for retrieval of multiple items with the aggregated item sizes rounded up to the next 4KB boundary. If you’re not going to index two items together in the same item collection (table or secondary index) and you don’t want to return both from every Scan, there’s no advantage to keeping them in the same table. But there are certainly some disadvantages that I’ll cover a little later. For all the other data operations (including multi-item like BatchGetItem, TransactWriteItems, etc.), DynamoDB doesn’t care if the items are in the same table or not—you’ll see the same storage/throughput metering and the same performance either way.
Sometimes, in order to bring data together into the same item collection, you need to make some adjustments to the primary key values. To be stored in the same table, the same primary key definition must be used. Examples of this include storing a numeric value as a string to match the data type of the partition key or sort key, or creating a unique value for the sort key where you didn’t necessarily have something important to store (using the same value as the partition key attribute is common for this when creating a “metadata” item in the collection).
Imagine a table for storing customer orders for shipping. The partition key is a unique numeric order identifier (data type is number), and you want to use a collection to store both a per-item record of items from the cart (identified by a numeric SKU) and tracking events (identified by a sortable UUID such as ksuid) for order processing. You want to retrieve these together for efficiency because the most common pattern is to provide a tracking page with the purchased items shown in addition to the tracking details. In this case, you’ll need to define the sort key with data type string, and convert values to store those numeric SKUs as strings. There’s a cost for this (because storing a number as a string consumes more bytes), but it’s worth it to get the benefit of the item collection.
Since it’s easy enough to accommodate these changes when writing your items into the table, a developer might as well just do it for all items and item collections, right? And put them all in the same table? Would it make sense for all DynamoDB customers to band together and store their data in one giant multi-tenant table? No—of course not. These techniques come with a cost and should only be used when they can be justified—to reap the benefits of item collections.
Closing thoughts
The valuable and valid part of “single table design” guidance is simply this:
Use DynamoDB’s schema flexibility and item collections to optimize your data model for the access patterns you need to cover. If you’re migrating from a relational database, you’ll likely end up with fewer tables than your old, fully normalized model. You’ll probably have more than one table, and you should use whatever number of Global Secondary Indexes (GSIs) are required to serve your secondary patterns.
Yep—that’s it. There really never was a need to create new terminology. “Single table design” confused some people, and sent many others down a painful, complex, costly path (details on this in an upcoming article) when it was taken too literally and then misrepresented as “best practice”. It’s time to just let this terminology go—stick with schema flexibility and item collections.
If you want to discuss this topic with me, get my thoughts on a DynamoDB data modeling question you have, or suggest topics for me to write about in future articles, please reach out to me on Twitter (@pj_naylor)—or email me directly!
Keep an eye out for a follow-up article where I’ll discuss the nuances of LSIs and GSIs and explain why “GSI overloading” is a bogus modeling pattern.
Appendix: What would I know about DynamoDB anyway?
Until recently, I worked at AWS. I started as a Technical Account Manager in 2016 within the account team that supports Amazon.com as an enterprise customer of AWS. My area of focus was helping Amazon to achieve some ambitious organizational goals: 1) migrate critical transactional database loads from traditional relational databases to distributed purpose-built databases (DynamoDB); 2) “lift and shift” second tier transactional loads from Oracle to Aurora; and 3) move all data warehousing from Oracle to Redshift. This was a fantastic experience all-around, but the part I loved most was witnessing the dramatic reduction in operational load and improvements in availability and latency that DynamoDB delivered. I worked with hundreds of Amazon.com developer teams to review their data models, teach them about managing DynamoDB limits, scaling, alarms, and dashboards. I sat in the war rooms for peak events like Prime Day as the point of contact for any kind of DynamoDB-related concerns which emerged with rapidly growing event traffic. It wasn’t easy for everyone to make the data model paradigm shift, but when this program was complete, all those developers quickly came to take all the DynamoDB advantages for granted. They got to focus a lot more time on things that made a difference for their customers—seeing this made a deep impression on me.
In 2018, I became a DynamoDB specialist solutions architect—part of a small team working with the largest (external) enterprise customers of AWS. I helped them develop effective and efficient DynamoDB data models for a wide variety of use cases and access patterns, and I taught many developers how to operate well with DynamoDB. My last 18 months at AWS was spent as a product manager for the DynamoDB service. I also provided hundreds of consultations to engineers across many AWS service teams as part of an “office hours” program for DynamoDB—reviewing data models, providing broader architectural guidance, and teaching about how DynamoDB works and the insights revealed by metrics.
All this is to say that I’ve seen a lot of production use cases for DynamoDB (from hundreds of requests per day to millions of requests per second), and I have a strong sense for the way that developers (at Amazon.com, inside AWS, and at many other companies around the globe) are actually using DynamoDB in practice.
Share