Oops, Momento ate 60% of my Lambda latencies!
Accelerate your app in minutes with a serverless cache.

Share
サーバーレス has radically enhanced developer productivity. The pay-per-use pricing model for serverless offloads the burden of capacity management while saving money. Overall, it enables developers to focus on their core business instead of reinventing the wheel with nitty gritty operational details.
But, there is a conundrum with serverless. As soon as you want to accelerate your pristine serverless stack with a cache, you have to go serverful. Setting up a caching fleet can be painful (read about the pain CBS Sports experienced with caching fleets). Serverless caching changes this—improving availability, elasticity, and scale.
Sure, you can cache locally, but local caches are not as effective on Lambda as they are on traditional servers that are processing hundreds of requests concurrently. Meanwhile, conventional wisdom states that DynamoDB is so fast that you don’t need a cache!
Intuitively, I knew that a cache should be faster than DynamoDB—but I wanted to prove it. Momento’s serverless cache made it really simple (and fast) to try this out: after building the application, it took me less than an hour to supercharge it with でキャッシング・インフラの将来を保証する, including deploying the new Lambdas!
You can try it yourself in under an hour, too. This example is fully open sourced in our demo repo with a hands-on tutorial, including a serverless application that can be built and deployed with SAM cli. The repo also contains a simple benchmark script that uses Locust to drive some small synthetic test traffic off your laptop to test service. We start with a basic serverless typescript REST API using DynamoDB and optimize with Momento as a cache. We emit metrics into CloudWatch and review the results on a CloudWatch dashboard.
Scenario
Imagine you are building a social network where each user has followers. Your front-end app has to download the names of each follower of the current user to render on the device. Our user model looks like this:
interface User {
id: string,
name: string,
followers: Array<string>,
}The API models a basic users API. The Lambda application will produce these CloudWatch metrics for you to explore and contrast:
- Momento: momento-get, momento-getfollowers
- DynamoDB: ddb-get, ddb-getfollowers
I used the /bootstrap-users endpoint to generate 100 test users with 5 random followers each. Subsequently, I exposed two endpoints:
GET /users and /cached-users
Makes 1 call to DynamoDB (/users) or Momento (/cached-users)
{
"id": "1",
"followers": [
"26",
"65",
"49",
"25",
"6"
],
"name": "Lazy Lion"
}Btw, I love jq for working with JSON.
I also exposed endpoints to get followers for a user (with or without a cache):
GET /followers and /cached-followers
Will make 1 call to either DynamoDB (/followers) or Momento (/cached-followers) for the passed user ID and then N (5 for this test) additional calls to either DynamoDB or Momento to look up each follower name.
[
"Angry Fish",
"Lazy Otter",
"Angry Sloth",
"Clingy Sloth",
"Dumb Lion"
]
The main code needed to implement this look-aside cache was extremely simple. You can see it here. We first look in Momento to see if the value exists and then fetch from DynamoDB and store for the next request if it does not.
const getCachedUser = async(userId: string): Promise => {
let user = await getUserMomento(userId)
if (!user) {
console.log("no user found in momento fetching from DDB")
user = await getUserDDB(userId)
// Set item in cache so next time can get faster
await momento.set("momento-demo-users", userId, JSON.stringify(user))
}
return user
}
const getUserDDB = async (id: string) => {
const dbRsp = await ddbClient.send(new GetCommand({Key: {id}, TableName: "momento-demo-users"}));
return dbRsp.Item as User
};
const getUserMomento = async (id: string) => {
const rsp = await momento.get("momento-demo-users", id)
const user = rsp.text()
if (user == null) {
return null
}
return JSON.parse(user)
};結果
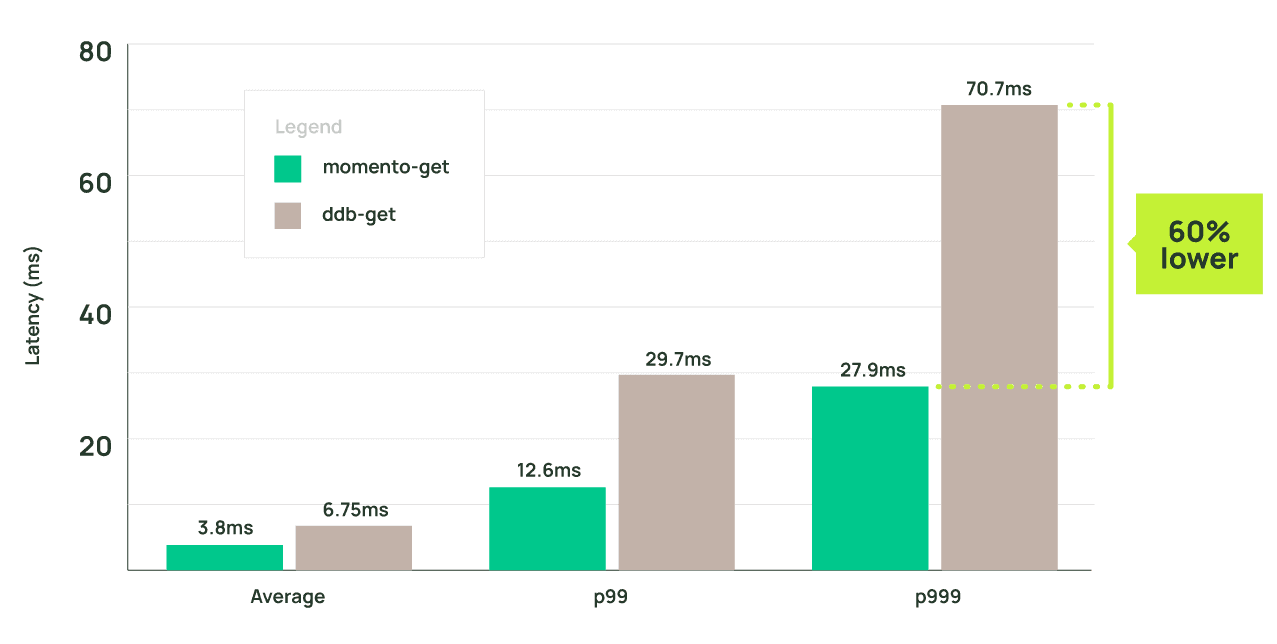
Looking strictly at average client-side latencies, we reduced the get-users average latency by ~43% (from 6.75 ms to 3.8 ms). For p99 we saw an over ~57% (12.6 ms vs 29.7 ms) reduction and for p999 we saw a 60% reduction (70.7 ms vs 27.9 ms).
Things get meaningfully more interesting for the Lambdas that require multiple DynamoDB calls. Even at average client side latencies, we see a ~53% drop (16.5 ms vs 7.61 ms). At p99, the latency drop is 72% (72 ms vs 19.5 ms). Finally, at p999, we were able to reduce our response times by 86% vs DynamoDB (536 ms vs 72.3 ms).
Lessons Learned
In less than an hour of work, Momento dropped my p999 latencies by over 86%. This means lower Lambda costs, happier users, and a more scalable system without having to worry about hot keys or hot partitions in DynamoDB. And adding Momento endpoints to our Lambda was fast! After getting the DynamoDB-backed Lambdas set up, adding each Momento endpoint took less than5 minutes—including creation of the cache, updating the Lambda to support a look-aside cache pattern, and deploying it. Third, tail latencies matter. You can see early indications that due to the multiple calls being made to DynamoDB, even the average latencies of Lambda start to skew towards the tail latencies of the DynamoDB calls.
Be on the lookout for free workshops we host where you can get hands on with this exercise. In the meantime, join our Discord—I’d love to answer any questions you have and hear your thoughts.
Share





