Maximize cost savings and scalability with an optimized DynamoDB secondary index
Understand projection and metering. Forget GSI overloading.

Share
DynamoDB Data Modeling Series
- What really matters in DynamoDB data modeling?
- Which flavor of DynamoDB secondary index should you pick?
- Maximize cost savings and scalability with an optimized DynamoDB secondary index (YOU ARE HERE)
- Single table design for DynamoDB: The reality
This is the third installment in a series of blogs about DynamoDB data modeling, mainly crafted to help DynamoDB developers understand best practice and avoid going down a regrettable path with misguided “single table design” techniques. In the previous episode—is this a show now?—we introduced local and global secondary indexes (LSIs and GSIs). This time we’ll dig deeper to understand which table data gets projected into a secondary index and how that contributes to throughput consumption. We’ll also tease apart one of the more recent twists in “single table design”—GSI overloading—and explain why it is generally a really bad idea with no actual upside. Ready? Off we go…
Which base table changes are relevant for projection into a secondary index?
When you define a secondary index, you get to choose which attributes will be copied (projected) from relevant item changes in the base table:
- ALL—all of the attributes in the base table item will be copied to the secondary index
- INCLUDE—only the named list of attributes will be copied (plus the primary key attributes for the base table and the secondary index—these are always included)
- KEYS_ONLY—only the primary key attributes for the base table and the secondary index will be copied
Here is how metering works for DynamoDB secondary indexes: every write you make to your base table will be considered for projection into each of your secondary indexes. If the change to the item in the base table is relevant to the secondary index, it will be projected, and there will be write unit consumption—metered in accordance with the size of the projected item view. There will be a storage cost for the projected data in the secondary index too. And remember—as explained in the first article in this series, Query と Scan (the only read operations available for secondary indexes) aggregate the size of all the items and then round up to assess read unit metering. If you keep the projected view of your items small, the index will cost less and will scale further before facing any kind of hot key concerns.
Consider projection very carefully for your secondary index. ALL seems simple but can be very costly and may inhibit scalability of your overall design. Only project the attributes that you really need.
There’s even more to this efficiency equation for secondary indexes. You’re probably wondering why I keep emphasizing the word relevant. Well, it’s because it is really important! First, because DynamoDB offers schema flexibility, the attributes defined as the key for your secondary index are not required to be present in every item in your table (unless they are part of the primary key for that table). If the index key attributes are not present in an item in the table, it will not be considered relevant for projection into the index. You can use this to create a “sparse” index—a powerful mechanism for filtering—to find the data you need at lowest storage and throughput cost.
An example might be a database which stores details of status for millions of jobs—the vast majority of them being completed. How can we make it easy for worker processes to find jobs which are in “submitted” status? For jobs which are in the relevant status, populate an attribute which indicates this, and create a secondary index which is keyed by this attribute. The attribute’s presence effectively becomes a flag—when the job is completed, remove this attribute—the job will no longer be visible in the secondary index for consideration by workers.
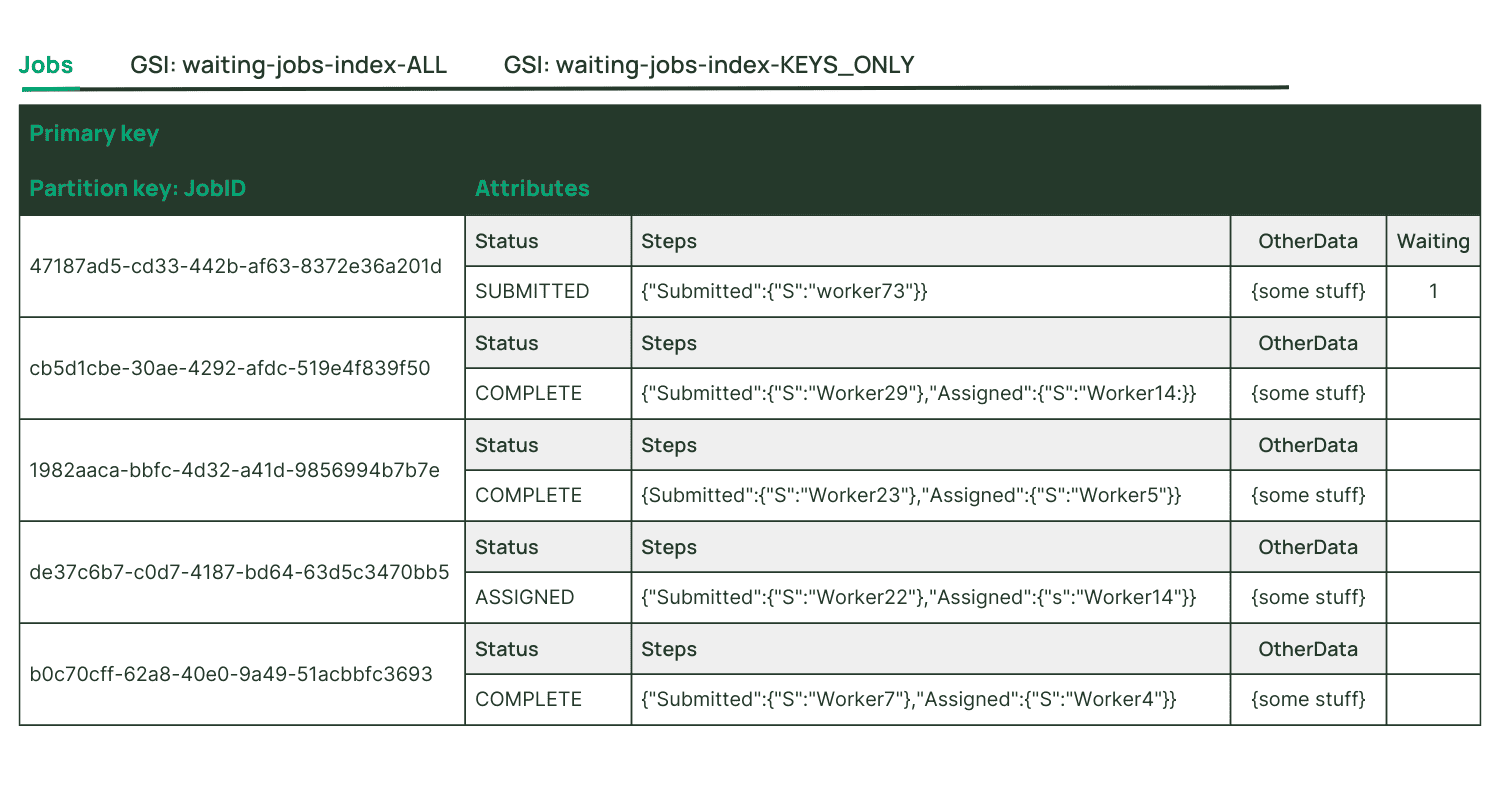
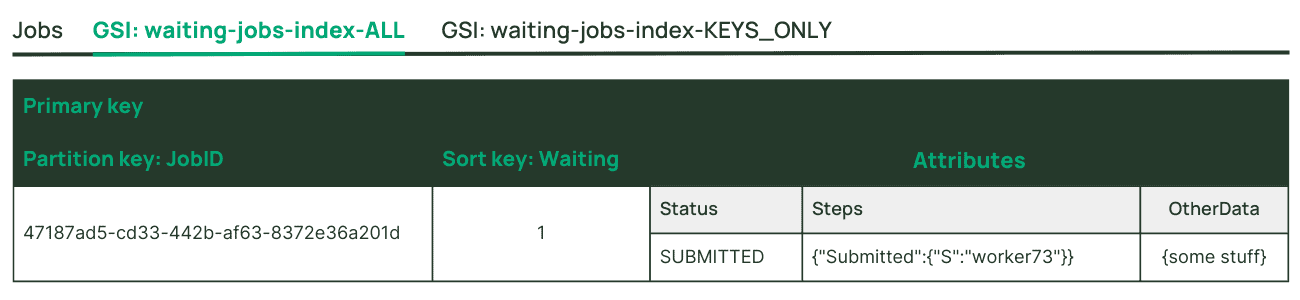
Now let’s imagine that as part of the workflow for jobs in submitted status, the job item in the table is updated five times to add various details in non-key attributes. If those attributes are projected to our submitted jobs sparse secondary index, the index will also need to be updated five times, consuming a bunch of write units. But our sparse secondary index really has no use for those attributes—they’re not relevant for the access pattern we need the index to serve. So we choose a KEYS_ONLY projection for the index—it keeps read unit consumption low, maximizes scalability for the worker processes, saves money on storage, and avoids a bunch of unnecessary writes for index projection.
This is worth repeating: only project the attributes that you really need.

What is “GSI overloading” and why is it a bad idea?
Back in 2017, Amazon teams were working hard to migrate their most critical workloads from relational databases to DynamoDB. They were learning to think differently about data modeling—looking beyond the familiar third normal form, and denormalizing into DynamoDB items and item collections. At that time, DynamoDB supported a maximum of 5 GSIs per table—hard limit. In some rare cases, there would be a team with a table which required more than 5 GSIs to cover all their access patterns. For those of us working to support those teams, there was a realization that some of the index needs could be sparse, and did not overlap. Maybe with some wonky adaptation we could use the same GSI to cover multiple access pattern requirements—could this help us to cheat on the GSI limit? Yes: it was a last resort, had terrible efficiency and operability implications—but sometimes it worked. We referred to it as “GSI overloading”.
Fast forward to December 2018, and DynamoDB increased the limit on GSIs per table to 20. Rejoice! No need for the ugly overloading hack henceforth… right? Well, the engineering team thought so—but then came some disturbing twists in the “single table design” story.
It turns out that if you do unnatural, unnecessary, complex, and inefficient things to push completely unrelated data into just one DynamoDB table for no reason, you’ll wind up having to create more secondary indexes for that table.
If you are designing with the goal of exactly one table (instead of prioritizing efficiency, flexibility, and scalability), you are more likely to encounter the limit on GSIs per table—and then the same “exactly one table” obsession drives a misguided desire to have exactly one GSI, which leads to overloading. This creates a whole slew of problems. There is actually no benefit to this technique—it’s a bad idea. Here’s why…
- You’ll likely need to make tradeoffs for projection that will cost you money and hurt your design’s scalability. The lowest common denominator is projecting ALL and defaulting to strings for primary key attributes (when numbers would be more efficient). Ouch!
- You lose the flexibility of being able to scan the secondary index and retrieve only the data you care about. That’s a powerful functionality gone—for no reason at all.
- One of the great things about GSIs is that you can delete them and recreate them as necessary. Deleting a GSI costs nothing. If you’ve mixed multiple index requirements into a single GSI and at some point you realize that you don’t need to index one of your patterns, you cannot just delete that GSI—you’ll have to (carefully) go back to the table and make expensive (and potentially risky) bulk updates. You really don’t want to be dealing with that.
Important takeaways
In short, there’s no benefit to “GSI overloading”—only negatives. Don’t do it! Also, if you care about cost optimization and scalability, consider sparseness and minimal projection when you design with DynamoDB secondary indexes.
In the next article in this series, I plan to build on what we’ve learned so far to explain where things went wrong with “single table design” and why interpreting it as exactly one table is a terrible mistake (that Amazon teams are not making).
If you want to discuss this topic with me, get my thoughts on a DynamoDB data modeling question you have, or suggest topics for me to write about in future articles, please reach out to me on Twitter (@pj_naylor)—or email me directly!
Share