各レイヤーでキャッシュすることでアプリのパフォーマンスを向上
遅いアプリにさようなら!究極のパフォーマンスを実現するために、アプリを上から下までキャッシュする方法を学びましょう。


Share
When we’re talking about applications, nothing is more important than speed and efficiency. But with so many moving parts in a modern architecture, data flow can introduce latency that slows everything down. That’s where caching comes into play! By storing data in a cache, applications can easily access it without having to process data every time a request is made.
This means faster load times and smoother performance, even during peak traffic times. And who doesn’t love speedy, seamless applications? So whether you’re building a serverless architecture or a traditional application, caching is the superstar solution that will keep your users happy and your applications running like a well-oiled machine. Get ready to take your applications to the next level!
Where can you cache to improve app performance?
Believe it or not, there are five levels of caching between your user interface and database! As Alex Debrie mentions in his blog post, each one has its own pros and cons. Let’s talk about what each one of these looks like in an application built on AWS.
Client-side cache
When a user visits your application, the browser sends a request to the server for the content. If the content has been cached on the client-side, the browser can retrieve it from the cache locally instead of making a new request to the server. This means that the data is instantly available, without any latency or delay caused by network traffic.
Client-side caching reduces the amount of data transmitted over the network. If the data is already cached on the client-side, the server doesn’t need to send it again, saving bandwidth and reducing server load.
API calls to your application can return headers that tell a browser to cache the data contained in the response:
- Cache-Control: This header controls how long the browser should cache the content, and whether it should be revalidated with the server on subsequent requests. It can have indicators like max-age, which specifies the maximum time the content can be cached, and no-cache, which forces the client to revalidate the content with the server before using it.
- Expires: This header specifies a specific date and time when the content will expire and should no longer be cached by the client.
- ETag: This header provides a unique identifier for the content, which the client can use to determine if the cached version is still valid. If the ETag has not changed, the client can use the cached version without making a new request to the server.
Content delivery network (CDN)
If you have a lot of content in your application, like pictures or videos, and you want users to see it quickly, you can use a content delivery network (CDN). An application built on AWS would use Amazon CloudFront as its CDN. CloudFront stores copies of your content in many different places around the world, making it really fast and easy for people to access your content, no matter where they are.
Plus, CloudFront caches your data, making it even faster to retrieve your pictures and videos. Even if your content is just a simple website hosted on Amazon S3, CloudFront can help make it speedy and accessible. To configure CloudFront and enable media caching in your app, you only need a few lines of code. See the example SAM template below.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
MyS3Bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: my-s3-bucket
MyCloudFrontDistribution:
Type: AWS::CloudFront::Distribution
Properties:
DistributionConfig:
Origins:
- Id: MyS3Bucket
DomainName: !GetAtt MyS3Bucket.DomainName
S3OriginConfig:
OriginAccessIdentity: !Ref OriginAccessIdentity
DefaultCacheBehavior:
TargetOriginId: MyS3Bucket
ViewerProtocolPolicy: redirect-to-https
ForwardedValues:
QueryString: true
MinTTL: 0
DefaultTTL: 86400
MaxTTL: 31536000
Enabled: trueLike all caches, you must configure a time to live (TTL) for the content, which tells the CDN how long to keep it before going back to S3 for a refresh.
API cache
Most RESTful APIs and WebSockets built on AWS use Amazon API Gateway. This service enables caching by storing responses to requests in a cache for a specified amount of time. When a caller makes a request to an API, API Gateway first checks its cache to see if there is a cached response for that request. If there is a cached response, API Gateway returns it directly to the client, without forwarding the request to the backend service.
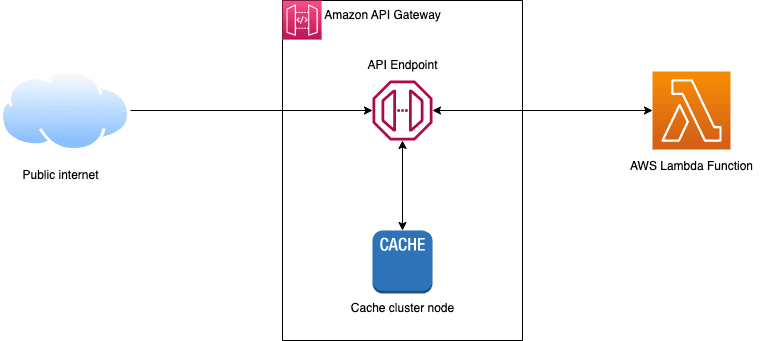
In addition to the performance boost this type of caching provides, it also stacks up on cost savings because API Gateway isn’t using computation resources to extract the data.
By default, API Gateway will cache requests on the request path, query string, and headers. But you can customize the cache key yourself to include or exclude any additional data.
AWS AppSync is a managed GraphQL service and has its own caching mechanism separate from API Gateway. It caches all the results from queries and mutation. Offering request-level and field-level caching, AppSync offers a great way to speed up execution and cut down on compute. You can even add configurable cache settings on individual resolvers, allowing you to cache data longer from data sources that change infrequently.
For JavaScript resolvers in AppSync, developers can use the Momento Node.js SDK to add caching in yet another layer.
Application Cache
When new requests come in from your user interface and make it past your API cache, your server-side implementation is the next opportunity to cache data. Data that is accessed frequently, is expensive to load, or is short-lived by nature are great opportunities for a cache.
Caching in this layer is a wonderful use case for Momento Cache. If your business logic makes a call to a 3rd party API that is notoriously slow or expensive, cache it! Take every opportunity you can to short-circuit expensive operations. This not only provides a faster experience for your end users, but once again cuts down on operational costs of your application.
You can optimize serverless backends or other distributed applications with Momento by taking advantage of its remote, centralized nature. No matter which execution environment or load-balanced server picks up a request, they all share a common cache, providing fast and easy access to data.
Database cache
Often thought of as the “only place to cache data”, databases are typically your last opportunity to cache data. The database is the workhorse of your application and any opportunity you have to take work off of it—you should.
Strategies like read-aside, write-aside, read-through, and write-through caching are all great approaches to taking stress off a tired database. The most common caching implementation is the read-aside cache, where a data fetch will query the cache before hitting the database. If the data is found in the cache, it is returned to the caller immediately. If it is not found, it is fetched from the database, populated in the cache, then returned to the caller.
On the write side, databases like Amazon DynamoDB and DocumentDB provide streams as a result of a data change, enabling you to build near-real-time cache update mechanisms. Whenever data is written to a record, data is streamed out and updated in the cache so it can be used in a subsequent lookup.
DynamoDB offers a caching option, DAX, that provides read- and write-through capabilities, which sounds great! However, it comes with its own set of troubles to deal with. DAX is a provisioned service, requiring consumers to configure, scale, and maintain their own cache clusters. Understanding the configuration and knowing how to right-size a cache cluster in DAX takes expert-level skills—and you still might not get it right! Contrast that with Momento Cache, where you get instant availability, elasticity, and pay-per-use pricing that gets you up and running in minutes.
Summary
Caching at so many different layers provides a number of opportunities to improve app performance and efficiency. In the cloud era, less compute means less cost. So not only are you providing a faster experience to your end users, you’re also keeping some extra spending cache (see what I did there) in your wallet!
After reading this, I’m sure you’re suddenly inspired to implement a cache everywhere. Just remember to think before you cache. Cache invalidation is hard and configuring an appropriate time to live for your data can sometimes feel like an exact science.
Start with one layer. Understand how it works and get to know how your users interact with your app. Once you’re comfortable with that layer—add another one. When you’re comfortable with that one, add another—so on and so forth.
Wondering where to start? You can never go wrong with a database cache. Try Momento’s step-by-step tutorial on implementing a cache in your application!
Share




