S3: The greatest AWS service ever, is not a Live Media Origin
Dive into how to supercharge S3 for live event origination with Momento

Share
It’s no secret that S3 is my favorite AWS service. It was the second AWS service to launch (after SQS beta) back in 2006. Today, it powers many other AWS services and much of the internet, storing quadrillion objects across millions of drives. At Momento, we take inspiration from how S3 was built and the foundational role it plays.
One of the key AWS design philosophies is to explicitly list non-goals alongside goals. S3 has been extraordinarily successful because it is optimized for durability, cost, and sustained throughput. However, optimizing these goals extremely well requires tradeoffs in the form of non-goals, such as tail latencies, tolerance for slightly higher error rates, and the maximum number of requests per second for a specific prefix.
S3 solves most problems, but it can’t solve everything. In order to excel in one dimension, another must be neglected.
Clearly, these tradeoffs were good decisions for what S3 was initially designed for, but there will always be use cases that need a different set of tradeoffs. For example, S3 is not suitable as an OLTP database. DynamoDB is the better choice because it offers lower tail latencies and error rates, even though it costs at least 10 times more per gigabyte of storage and throughput.
There are many things you could build on S3 but probably shouldn’t. Today, we will dive into why media origination for live events fits this category.
What is a live origin server?
A live media origin is the underlying storage system and server for the data that composes a live media stream. It typically sits between the encoder or packager and the CDN, which communicate with the origin via HTTP requests.
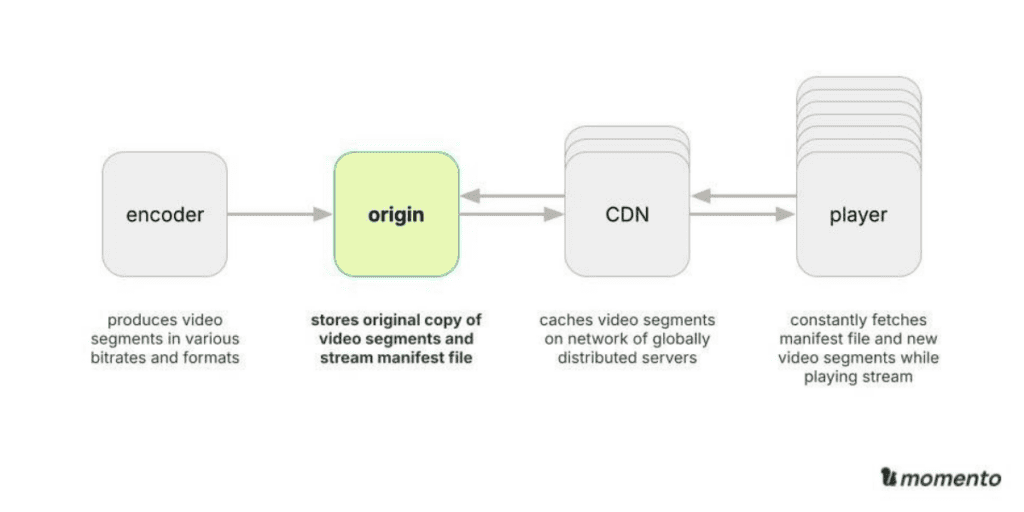
For an HLS (HTTP Live Stream) stream, a typical live encoder constantly pushes video and audio segments to the origin, then updates the manifest file. The gold standard for live event segment size is ~2 seconds, which is reproduced multiple times with various encodings and bitrates. At the same time, each CDN PoP hammers the origin to fetch the next segment for viewers. All of this creates a firehose of real-time operations with high sensitivity to read and write latency.
This perfect storm causes even small glitches on the order of tens of milliseconds (!!) to compound and erode the viewer experience. Each incremental bit of latency chips away at the player’s short data buffer. Unlike more relaxed scenarios such as web browsing and analytical workflows, the margin for error in live media is razor-thin.
Doing the math for SLAs
S3 offers a very respectable single-region error rate SLA of 99.9% or 1 error out of every 1000 requests. However, the video manifest and segment files are updated tens of thousands of times during a live event like the soccer World Cup, so we should expect tens of write errors. To estimate read errors, multiply by one hundred.
Now, each error results in a retry which probably succeeds but also introduces hundreds of milliseconds of delay via retries, timeouts, etc. This delay propagates and multiplies out through the CDN to impact tens or hundreds of thousands of players desperately trying to fetch the latest segments. When these delays accumulate to the point that a player is starved for stream data, it results in the dreaded “buffering”. ☠️
When all you have is a hammer…
As I mentioned earlier, S3 makes deliberate tradeoffs in pursuit of durability, cost, and sustained throughput. These are not the dimensions that matter most for live streaming, but they come at a cost of the dimensions that impact viewer experience.
Evaluating S3’s key dimensions against live streaming requirements:
- Durability – Eleven 9’s of annual durability is fourteen 9’s of durability across a 4-hour live event. Does that really make sense for a real-time application with an SLA of just three 9’s?
- Cost – Price per GB is crucial for sustainable long-term retention of content. However, “live” data is necessarily constrained in size to the most recent N hours.
- Sustained throughput – Throughput does matter, but S3 has the wrong kind of throughput for a live stream composed of many tiny objects. What truly matters is request throughput.
So, if the above dimensions aren’t as crucial for a live media origin, what dimensions are important? Let’s work backwards from what we know:
- Time-to-first-byte – Because a live stream is composed of many tiny objects, total throughput is closely correlated with Time-To-First-Byte (TTFB).
- Near-zero error rate – Low error rates are crucial to avoid the catastrophic impact of latency from retries. A live origin requires an error rate SLA of at least five 9s.
- Tight tail latencies – The 99.99% latencies matter because of the way latency accumulates and amplifies through the CDN to players. Each player has less than 2 seconds to successfully retrieve the next segment of data!
- Mitigate hot shards – Consistent performance for similarly-named keys sounds silly – until your stream is kneecapped by a hidden sharding constraint. The largest broadcasters actually file a ticket to pre-shard their S3 buckets before an event!
While S3 is an amazing, foundational storage service, it’s also clearly a mismatch for live-streaming scenarios. And to be clear, that’s not a problem with S3. Just as we should use hammers for nails rather than screws, we should use S3 for the many things it is the best at.
Building a better live origin
We know that an ideal live origin needs to optimize for TTFB, low error rates, tight tail latencies, and hot shards. It just so happens that a well-known cloud component accomplishes almost exactly this: the in-memory cache!
Of course, it’s not a perfect fit. If you just spin up a Redis or Elasticache cluster, you’ll be sorely disappointed by the operational complexity compared to S3—managing cluster capacity, setting up sharding and failover, building features like access control and hot key mitigation, and wiring up a gateway and Lambda functions to handle HTTP requests. Finally, and most importantly, you’ll need a solid, dedicated operational team to ensure the service remains robust and available.
Enter Momento, the most robust caching platform in the world! Written from scratch in Rust, Momento was built by media engineers with a track record of delivering high-performance, hyperscale systems for AWS and other top tech companies. Momento’s two-tiered architecture integrates the caching engine with an HTTP API, fine-grained access control, and secondary fan-out caches that mitigate hot keys.

Momento serves mission-critical workflows for global media brands like Paramount, DIRECTV, and Proseiben at a scale of millions of requests per second (RPS). Our key differentiators are a robust architecture, extensive subject matter expertise, and operational excellence as we function as an extension of your platform team. To learn more about how Momento can help you deliver the ultimate viewer experience, visit gomomento.com.
Share





