How a centralized cache elevates serverless applications
Boost performance, bypass service limits, and save time and money by incorporating a centralized cache into your solution.

Share
Serverless applications are known for a few things. They scale to meet demand, including down to 0. They are fault-tolerant in the event of a transient network outage. They cost almost nothing to run when compared to containers or traditional software deployments in most cases.
And they’re known for speed. Serverless applications are fast.
Not necessarily because the infrastructure is better, but because there are operational constraints that naturally lead to a more consistent, predictable, and scalable runtime. The pricing model for serverless services is simple. Pay for what you use. The faster your software responds to events, the lower your bill will be at the end of the month.
There are many ways developers tune their serverless applications to achieve breakneck speeds. In fact, I share 9 ways to optimize serverless apps ranging from reusing HTTP connections, to connecting API Gateway directly to downstream services, to caching variables locally in the Lambda execution environment. But an important optimization is missing from my list: implement a central cache.
Performance, behavior, and capabilities vary wildly based on the type of cache you decide to use in your application. Alex Debrie wonderfully describes the major differences in his post on understanding the different cache types.
Serverless applications need serverless caching. When your entire application elastically scales with demand except for your cache, you run into issues with throttling and data integrity. But when your cache scales at the same capacity as your app, there is no other experience like it. With Momento, a truly serverless cache, you can quickly and easily open the door to centralized caching to enable lightning fast access to data across your application.
Why local caching isn’t enough
Serverless services are incredible feats of engineering. They completely abstract away the complexities of traffic-based scaling from consumers, leaving them with a highly available application that responds at the drop of a hat.
But in order to understand how to appropriately cache data, we need to take a quick peek under the covers at how services like AWS Lambda work to meet demand.
When a Lambda function is invoked, it creates an execution environment. This environment is the container that will initialize connections and run your code. When your code has finished running, the environment stays alive for a period of time in anticipation of another invocation. Subsequent invocations skip the initialization step and reuse data stored outside of the main function handler.
Consider this Lambda best practice from AWS:
Take advantage of execution environment reuse to improve the performance of your function. Initialize SDK clients and database connections outside of the function handler, and cache static assets locally in the /tmp directory. Subsequent invocations processed by the same instance of your function can reuse these resources. This saves cost by reducing function run time.
A Lambda execution environment can only respond to one request at a time. If another request comes in while an execution environment is running your code, another one will initialize to meet the demand.
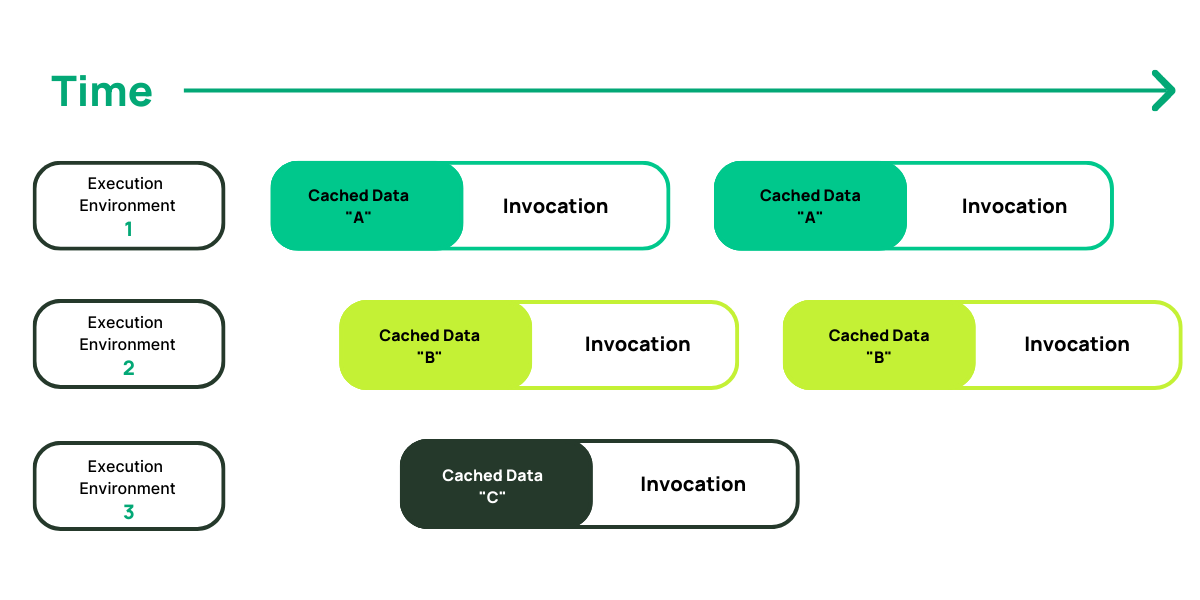
In the example above, we have a total of 5 invocations that result in 3 separate execution environments. When a request comes in while an invocation is running, if there is no “free” execution environment, a new one is created.
When a request comes in and an execution environment is available, it is used instead of initializing a new one. When the environment is reused, the subsequent invocation has access to the locally cached data. This locally cached data is scoped to the execution environment and, once it shuts down, is gone forever.
With the 3 execution environments above, we have 3 sets of locally cached data. If all invocations were performing the same lookup, say on an S3 object, you would have a cache miss on the first invocation of each execution environment. Not only does that increase cost, but it could also cause confusion when debugging due to the nature of a local cache. If the data was cached in a centralized, remote location, you’d have a single place to look instead of multiple ephemeral local stores.
Imagine a Lambda function that loads metadata and thumbnails for items in a store. A new product comes along that gets a lot of hype. Thousands of people put the item in their cart for presale. When the product comes online, a wave of traffic hits the function, causing it to horizontally scale and initialize thousands of new execution environments. Each new execution environment has to load the data so it can be locally cached.
Over time, cache misses like this build up. You call the SDK over and over again, loading the same data repeatedly, incurring the costs of doing a lookup. With S3 objects, it gets expensive real fast.
The subsequent calls on each execution environment would be cache hits and return the value without doing an extra lookup call. So using the execution environment as a local cache gets us some performance and cost reduction, but there has to be a better way.
Centralized cache to the rescue
Serverless applications certainly have their use for local caching, like SDK client initialization and database connection management. But when you’re trying to reduce the number of calls to downstream services, a centralized cache becomes your best option.
With a remote, centralized cache, you gain the ability to share data across not only execution environments, but your entire backend! However, just because you can doesn’t mean you should. A central cache is a powerful weapon, but if used without intentional forethought it could turn into a nightmare.
That said, if you’ve done the planning and are responsibly implementing a cache in your application, some exciting doors open up.
When it comes to sharing data across execution contexts, you can cache data in a read-aside cache. A read-aside cache is a lookup in a central cache prior to fetching data from a persistent datastore. If you get a cache hit, return that value. If you miss, load the data from a datastore like DynamoDB.
Consider a Step Function workflow that loads data from multiple sources, combines bits and pieces, and performs additional transformations and validations before finally saving the end result to DynamoDB.
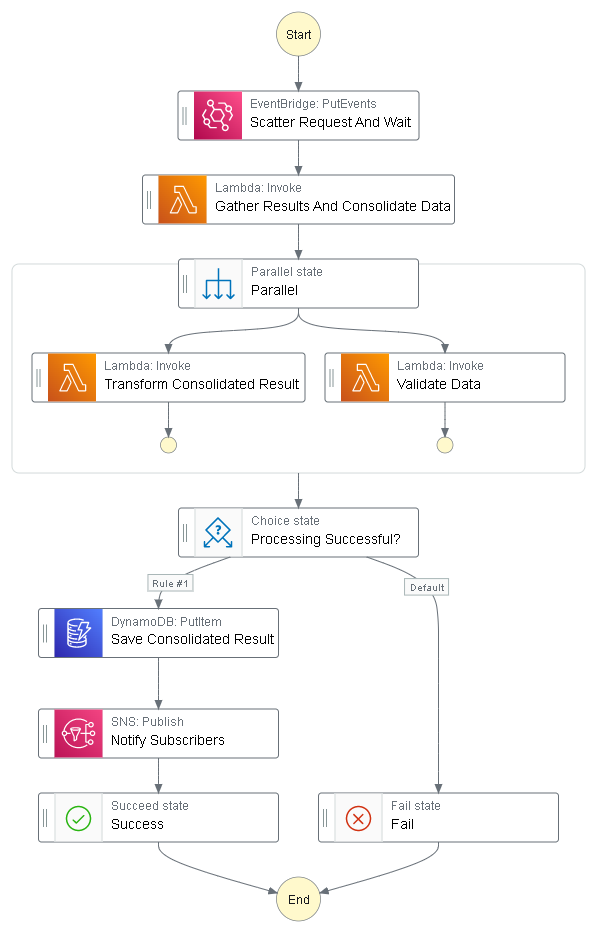
The data being consolidated is rather large and would quickly cross the 256KB state data size limit in Step Functions. This workflow also gathers data from other microservices using EventBridge, which has a max message size limit of 256KB.
These limits make it impossible to send the data back and forth via the payload of an event or to keep it as data in the Step Function execution context. Instead, we use a central cache to temporarily store the data and pass around cache keys in our events.
Momento has a soft item size limit of 1MB, resulting in a 4x increase in data capacity for our state machine! If your item sizes exceed 1MB, you can reach out to the Momento team on Discord or via contact form to further increase this limit.
Traditionally, this would be worked around by storing the item in S3 and loading the data on demand in each Lambda function. When providing access to data across microservices the same approach applies, but access is granted via a presigned url.
Since Momento is a remote caching system, we don’t need to worry about the high latency of loading data through S3. Instead, we have a central location that all microservices can access with blazing fast response times.
Conclusion
Due to the stateless nature of serverless applications, caching has become a difficult problem again. Most modern caching solutions don’t fit well in serverless applications mostly because they aren’t… well… serverless.
AWS services like DAX or ElastiCache offer caching features, but they also come with the overhead of cluster management, failover configuration, and provisioned resource pricing.
A serverless application needs a serverless cache, which is where Momento comes in. The remote, centralized, serverless nature of Momento offers an automatic scaling, large item size storage, and low-cost alternative.
By responsibly implementing a cache in your serverless application, you’ve built a way to bypass size limitations of many AWS services. You also drastically cut down on costs and discovered a way to make service-to-service communication a little easier.
Caching won’t address all the pain points in building serverless applications—far from it. But it will enable you to build solutions quickly without implementing workarounds to avoid serverless service limits.
So what are you waiting for? Give it a shot today with Momento. You can start for free. If you still have questions or want to talk strategy, reach out on Twitter or join the Momento Discord!
Follow me on Twitter (@AllenHeltonDev) for more serverless content. You can also join my Serverless Picks of the Week newsletter to get perspectives right in your inbox.
Share




